
No Experience in Data Engineering? Start Here
Data engineering is one of the fastest-growing fields, offering lucrative salaries and job security. If you're new and want to start, focus on these essentials:
- Learn Python and SQL: These are the backbone of data engineering. Python helps with automation and data processing, while SQL is crucial for querying and managing databases.
- Master Key Tools: Get hands-on with platforms like Databricks (data lakehouse and AI), Snowflake (cloud data warehouse), and Apache Airflow (workflow orchestration).
- Build Projects: Start with simple ETL pipelines or projects like weather data analysis and user behavior tracking. These help you practice ingestion, transformation, and storage techniques.
- Follow a Learning Plan: Dedicate 6–12 months to learning Python, SQL, orchestration tools, and cloud platforms. Work on projects to build a portfolio.
- Use Resources: Books like Fundamentals of Data Engineering and courses from platforms like DataExpert.io can guide your journey.
The demand for data engineers is high, with U.S. salaries averaging $106,966 annually. Start small, practice consistently, and build your skills step by step.
How I would learn Data Engineering in 2025 (if I could start over) – Built by a Data Engineer
Core Skills You Need to Start
If you're eyeing a career in data engineering, it's time to focus on the essentials. A degree in computer science? Not mandatory. Instead, channel your energy into mastering Python and SQL - the backbone of nearly every data engineering task, whether you're building pipelines or troubleshooting cloud warehouses.
With consistent effort over 6–12 months, you can become job-ready. In fact, learners who complete structured data engineering programs report an average salary increase of $30,000. The key? Dive into the fundamentals and learn by doing. Watching endless tutorials won't cut it - hands-on practice is what builds confidence and competence. Nail these foundational skills, and you'll be ready to tackle the broader data engineering toolkit.
Learning Python for Data Engineering
Start with the basics: variables, data types, lists, loops, and conditionals. Once comfortable, move on to functions, dictionaries, object-oriented programming (OOP), and handling dates and times.
But Python's role in data engineering goes beyond basic programming. You'll need to get familiar with libraries like Pandas for cleaning and transforming data, NumPy for numerical operations, and PySpark for processing massive datasets in distributed systems. To round out your skill set, learn command-line tools (Unix/Linux), version control with Git, and how to write unit tests and logs effectively.
Interactive platforms are a great way to start - they provide instant feedback as you write and test your code, helping you learn faster.
Learning SQL for Data Querying
While Python automates workflows, SQL is your go-to tool for querying and managing data. As Airbyte succinctly puts it:
SQL is fundamental for database operations and querying.
SQL is indispensable for extracting, transforming, and loading (ETL) data, as well as troubleshooting cloud databases like Snowflake, BigQuery, and Redshift. Start with the basics: JOINs, WHERE clauses, GROUP BY statements, subqueries, and common table expressions (CTEs). These are the building blocks of production-grade data pipelines. As you advance, focus on writing idempotent queries - queries that deliver consistent results without duplicating data.
SQL's staying power is undeniable. Vino Duraisamy, Developer Advocate at Snowflake, highlights its longevity:
SQL has been around since 1975, and it is here to stay!
Want to practice without breaking the bank? Many cloud platforms offer free trials. For instance, Snowflake provides a 30-day trial (or 90 days for students), allowing you to write queries against real-world datasets for free.
Mastering Python and SQL will open the door to the expansive world of data engineering tools and platforms. These two skills are your launchpad to success.
Key Tools for Beginners
Once you've got a handle on Python and SQL, it's time to dive into the tools that power modern data pipelines: Databricks, Snowflake, and Apache Airflow.
Overview of Databricks, Snowflake, and Airflow
Databricks is a versatile platform built on Apache Spark, Delta Lake, and MLflow. It uses a Data Lakehouse architecture, blending the flexibility of data lakes with the structure of data warehouses. With built-in generative AI, it supports coding, debugging, and query optimization. Databricks' Notebooks let you work seamlessly with SQL, Python, Scala, and R. Plus, its 14-day free trial gives you access to tools like Auto Loader for incremental data ingestion and the AI Playground for no-code prototyping.
Snowflake serves as a cloud-based data warehouse with a SQL-driven interface. It separates storage from compute, enabling multiple queries to run simultaneously without slowing down performance. The platform's Time Travel feature allows you to restore data to a previous state, which is especially handy for fixing errors. Snowflake also offers a Marketplace with public datasets ready for analysis. New users can take advantage of a 30-day free trial, including $400 in credits, and there's no need to provide payment details. Starting with an X-Small virtual warehouse and enabling auto-suspend helps conserve credits.
Apache Airflow is all about orchestrating data workflows using Python-based DAGs (Directed Acyclic Graphs). Its web interface allows you to monitor pipeline health, review logs, and track task failures. Originally created at Airbnb to address data lineage challenges, Airflow is open-source and free to use. However, managed versions offered on platforms like AWS or Google Cloud come with additional service costs.
Together, these tools form the backbone of modern data engineering, helping you turn your foundational skills into practical applications.
Tool Comparison for Beginners
| Feature | Databricks | Snowflake | Apache Airflow |
|---|---|---|---|
| Primary Focus | Unified Data + AI (Lakehouse) | Data Warehousing & Analytics | Workflow Orchestration |
| Primary Language | Python, SQL, Scala, R | SQL | Python |
| Beginner Safety Net | AI-assisted coding & debugging | Time Travel (undo errors) | Visual monitoring UI |
| Free Trial | 14 days | 30 days with $400 credits | Open-source (free) |
| Best For | Heavy ETL, Machine Learning, AI | Analytics, BI, Data Sharing | Scheduling and managing pipelines |
| Data Ingestion | Auto Loader (incremental loading) | Snowpipe & Marketplace (no-ETL) | Operators for task-based transfers |
Your choice of tool depends on your focus: go with Snowflake for SQL-heavy analytics, Databricks for machine learning and ETL processes, and Airflow for managing complex workflows. The great part? You don’t have to limit yourself to just one - data engineers often use all three based on the task at hand.
These tools lay the groundwork for hands-on projects, helping you sharpen your data engineering expertise.
sbb-itb-61a6e59
Building Hands-On Skills with Projects
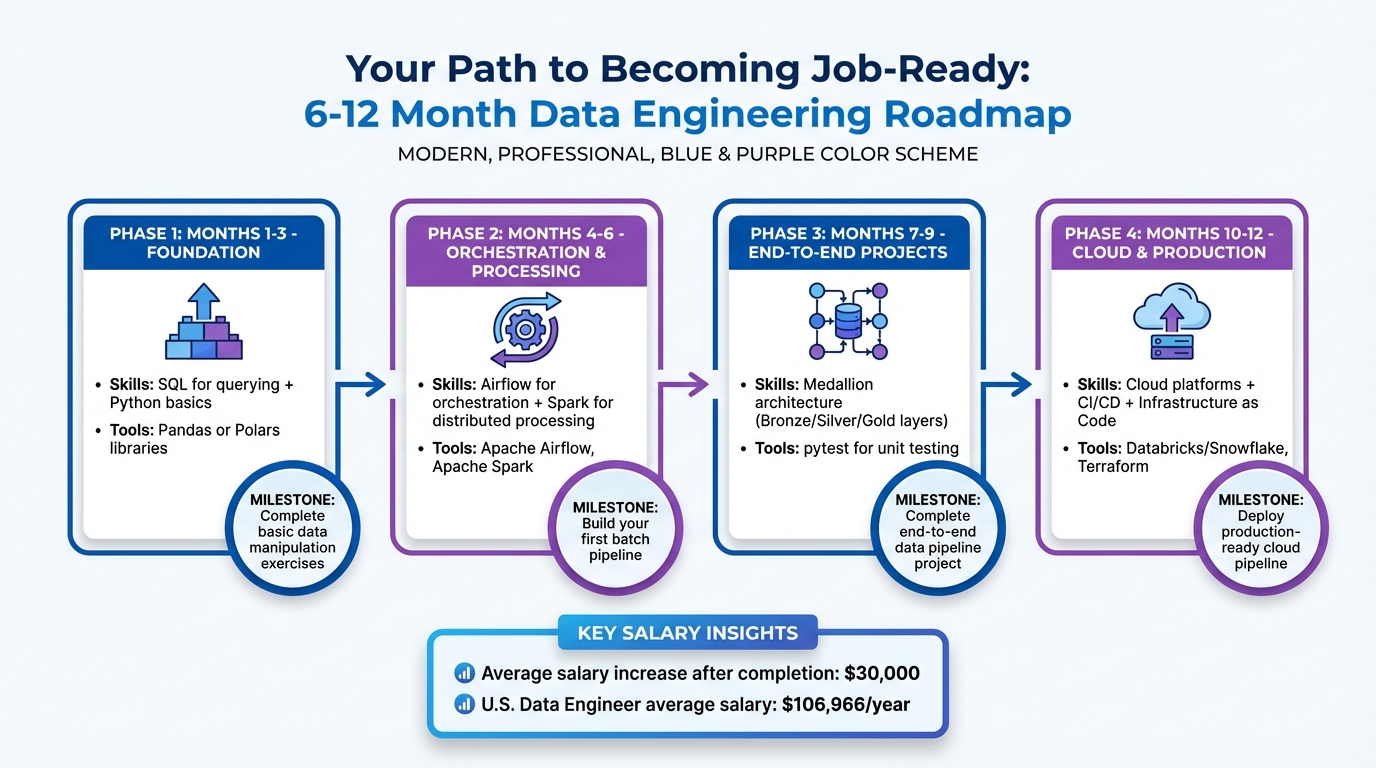
6-12 Month Data Engineering Learning Roadmap for Beginners
Now that you’ve got a solid foundation in Python and SQL, it’s time to roll up your sleeves and dive into hands-on projects. Why? Because applying what you've learned in real-world scenarios is where the real growth happens. Think of these projects as your training ground to practice the "Big Data Blueprint" - a framework that includes Connect (Ingestion), Buffer (Messaging), Processing (Batch/Stream), Store (Warehousing), and Visualize (Dashboards). Mastering this workflow is key to building a successful career in data engineering.
Beginner Data Engineering Projects
A great starting point is working on projects that illustrate the Medallion architecture. This three-layer approach takes raw data and transforms it into refined, analysis-ready formats. Here’s how it works:
- Bronze Layer: Extract raw data and standardize types.
- Silver Layer: Clean and model the data using dimensional techniques like Fact and Dimension tables.
- Gold Layer: Create stakeholder-specific aggregations or "One Big Table" formats for easy analysis.
For beginners, a Weather Data Pipeline is an excellent choice. Use Python to pull data from the Open-Meteo API, store it in PostgreSQL running inside a Docker container, and write SQL queries to analyze temperature trends. This project introduces you to API integration, containerization (a must-have skill these days), and SQL basics - all without incurring cloud costs. Instead of relying on Pandas for transformations, consider using Polars, a faster alternative gaining popularity in the data engineering world.
Another beginner-friendly project is building a User Behavior Analytics pipeline. Use Airflow to orchestrate tasks, Spark for distributed processing, and DuckDB for storage. This end-to-end batch project will teach you how to schedule workflows, manage large datasets, and implement idempotency - ensuring consistent, duplicate-free outputs even if a failed task is re-run. Organize your work with a clear directory structure, such as:
/configfor setup files/datafor raw and processed datasets/etlfor extract/transform/load scripts/testsfor data integrity checks
"Data engineering is about building pipelines that run reliably every single day, handling the messy reality of production data." – Dataquest
Documenting your challenges and solutions is just as important as completing the project. This not only helps you learn but also creates a portfolio that impresses potential employers. To ensure data quality, integrate automated checks using tools like Great Expectations. These checks can validate record counts and flag null values before data reaches stakeholders.
Now, let’s see how you can align these projects with a structured learning roadmap to get job-ready within 6–12 months.
6–12 Month Learning Roadmap
Getting job-ready as a data engineer typically requires 6–12 months of focused learning and practice. Here’s a suggested timeline to guide your journey:
- Months 1–3: Build a strong foundation in SQL for querying and Python basics with libraries like Pandas or Polars.
- Months 4–6: Learn Airflow for orchestration and Spark for distributed processing. Use these tools to build your first batch pipeline.
- Months 7–9: Tackle an end-to-end Medallion project. Add unit tests using
pytestto ensure your pipelines are robust. - Months 10–12: Focus on cloud-native platforms like Databricks or Snowflake. Learn to set up CI/CD pipelines and use Infrastructure as Code tools like Terraform.
Top Resources for Learning Data Engineering
The resources below are designed to deepen your knowledge and help you tackle real-world data engineering challenges.
Recommended Books for Beginners
Books are a great way to build a solid foundation in data engineering. One standout is Fundamentals of Data Engineering by Joe Reis and Matt Housley. This book provides an excellent overview of the data lifecycle, architecture, and modern data stack without tying itself to specific tools. As data engineering writer Veena describes it:
This is the roadmap for the modern data engineer. It connects the dots between tools, architecture, and cloud strategy.
For a deeper dive into distributed systems, replication, consistency models, and scalability, Designing Data-Intensive Applications by Martin Kleppmann is a must-read. Many industry professionals consider it essential for anyone serious about backend or data engineering. If you're interested in mastering dimensional modeling - a key part of business intelligence - The Data Warehouse Toolkit by Ralph Kimball and Margy Ross is the go-to guide for understanding star and snowflake schemas.
For those looking to explore streaming data processing, Streaming Systems by Tyler Akidau covers event-time, windowing, and watermarks in detail. Additionally, for hands-on practice with cloud platforms, platform-specific cookbooks for AWS (published in November 2024), Azure, Google Cloud Platform, Snowflake, and Databricks offer practical ETL/ELT recipes you can start using immediately.
Pair these readings with structured, hands-on learning experiences to solidify your skills.
Courses and Programs from DataExpert.io Academy
Books provide the theory, but practical programs help you turn that knowledge into job-ready skills. DataExpert.io Academy offers structured courses designed to take you from beginner to professional.
The Winter 2026 Data Engineering Boot Camp is a 5-week intensive program priced at $3,000. It includes lifetime access to course content, five guest speaker sessions, and a capstone project. This program is perfect for those with intermediate Python skills and some experience with Spark.
If you're just starting out, the Finish 2025 Strong 50-Day Data Challenge is a free program that builds consistent technical habits through daily coding challenges and quizzes. For more comprehensive learning, the All-Access Subscription offers over 250 hours of content covering platforms like Databricks, Snowflake, and AWS. It also includes community support and is priced at $125 per month or $1,500 per year. All programs emphasize hands-on, end-to-end projects that are perfect for building a standout portfolio.
Conclusion: Take the First Step Toward Your Data Engineering Career
Data engineering offers a rewarding path for those ready to dive in. To get started, focus on mastering Python and SQL, familiarize yourself with cloud platforms like AWS or Azure, and work on projects that highlight your abilities.
The demand for data engineers is growing rapidly, driven by the explosion of global data volumes.
Begin with something simple, like an ETL project that extracts data from a CSV file and loads it into a local database. Use GitHub to display your projects, showcasing your ability to solve practical challenges. Make sure your pipelines are designed to be idempotent - producing consistent results no matter how many times they're run. Add clear README files and design diagrams to explain your process. This hands-on approach lays a strong foundation and sets you up for success as you explore further learning opportunities.
FAQs
How can I effectively practice Python and SQL to start a career in data engineering?
The most effective way to get better at Python and SQL for data engineering is by mixing structured learning with hands-on projects. Start with the basics: learn Python essentials, including working with libraries like pandas for data manipulation, and get comfortable writing SQL queries to manage and analyze data.
To put your skills into action, try working on small, practical projects. For instance, grab a public dataset, use Python to clean and transform the data, and then load it into a local database like SQLite or PostgreSQL. Once the data is in the database, practice writing SQL queries to extract insights or join tables. To build solid habits, use version control tools like Git to track your progress and manage your code. Setting aside at least 10 hours a week for hands-on practice can help you stay consistent and see steady improvement.
By balancing tutorials, mini-projects, and regular practice, you'll quickly gain the foundational skills needed to excel in a data engineering role.
What’s the best way to choose data engineering tools for a beginner project?
To pick the best data engineering tools, start by pinpointing what your project requires. Look at factors such as your data sources, the volume of data you'll handle, and how quickly you need to process it. For handling large-scale, fast-moving data, modern ELT tools are a solid choice. On the other hand, smaller or periodic tasks might be better suited to traditional ETL solutions.
Also, consider your team's expertise. If Python is in your wheelhouse, open-source tools like Apache Airflow for workflow orchestration or Apache Spark for data processing could be excellent fits. If you prefer a managed, cloud-based setup, platforms like Databricks provide features like declarative pipelines and seamless integration with cloud storage, making them user-friendly and efficient.
Lastly, weigh factors like cost, scalability, compatibility with your current systems, and the level of support available. Aligning these considerations with your project’s goals will help you choose tools that not only meet your needs today but also adapt as your ambitions grow.
What are some beginner-friendly projects to start learning data engineering?
If you're stepping into the world of data engineering, working on hands-on projects is one of the best ways to develop practical skills. Start small with manageable pipelines that introduce you to key tools and concepts commonly used in the field.
- Batch ETL Pipeline: Build a workflow that takes raw data from CSV or JSON files, transforms it with tools like Apache Spark or DuckDB, and loads it into a cloud data warehouse such as Snowflake or Amazon Redshift. Use Apache Airflow to orchestrate the tasks, giving you experience with scheduling, managing dependencies, and handling errors.
- Real-Time Data Stream: Set up a project to simulate clickstream data using Apache Kafka, then process it in real-time with tools like Apache Flink. This will help you understand event streaming, real-time processing, and how to store the results for further analysis.
- End-to-End Data Workflow: Use publicly available datasets, such as COVID-19 statistics, to clean and transform data with Python and Pandas. Store the processed data in a cloud service like Amazon S3, query it using Amazon Athena, and create visualizations on a dashboard. Automate the workflow with schedulers like Airflow or Prefect to tie everything together.
These beginner-friendly projects are perfect for building confidence while staying budget-conscious. They also help you get comfortable with essential tools like Python, SQL, cloud storage, and orchestration platforms.