Blog

Complete Guide to Databricks Lakehouse and Delta Lake
Learn Databricks Lakehouse, Delta Lake, Unity Catalog, SQL warehouses, and Azure-Fabric links in one guide for data teams.

Base64 Encoder
Encode text to Base64 or decode Base64 back to readable text instantly in your browser. Fast, private, and easy to use.

Case Study: Caching with Databricks for Faster Analytics
Cut scans from 2.3TB to 8GB and reduce compute costs 73% using Disk Cache, Spark cache, SQL result cache and improved file layout.

Cron Expression Generator
Create, validate, and understand cron schedules in your browser with guided controls, real-time output, and plain-English explanations.

Complete Guide to Azure Data Factory for Data Engineers
Learn Azure Data Factory, ETL pipelines, core ADF components, scheduling, monitoring, and data engineering basics in Azure.

JSON Formatter
Paste raw JSON, format or minify it instantly, and catch exact syntax errors right in your browser. Fast, private, and easy to copy.

AWS Data Engineering: Beginner's Roadmap & Basics
Learn AWS data engineering basics with Python, SQL, Spark, Google Colab, data structures, common errors, JSON cleanup, and cost-aware coding.
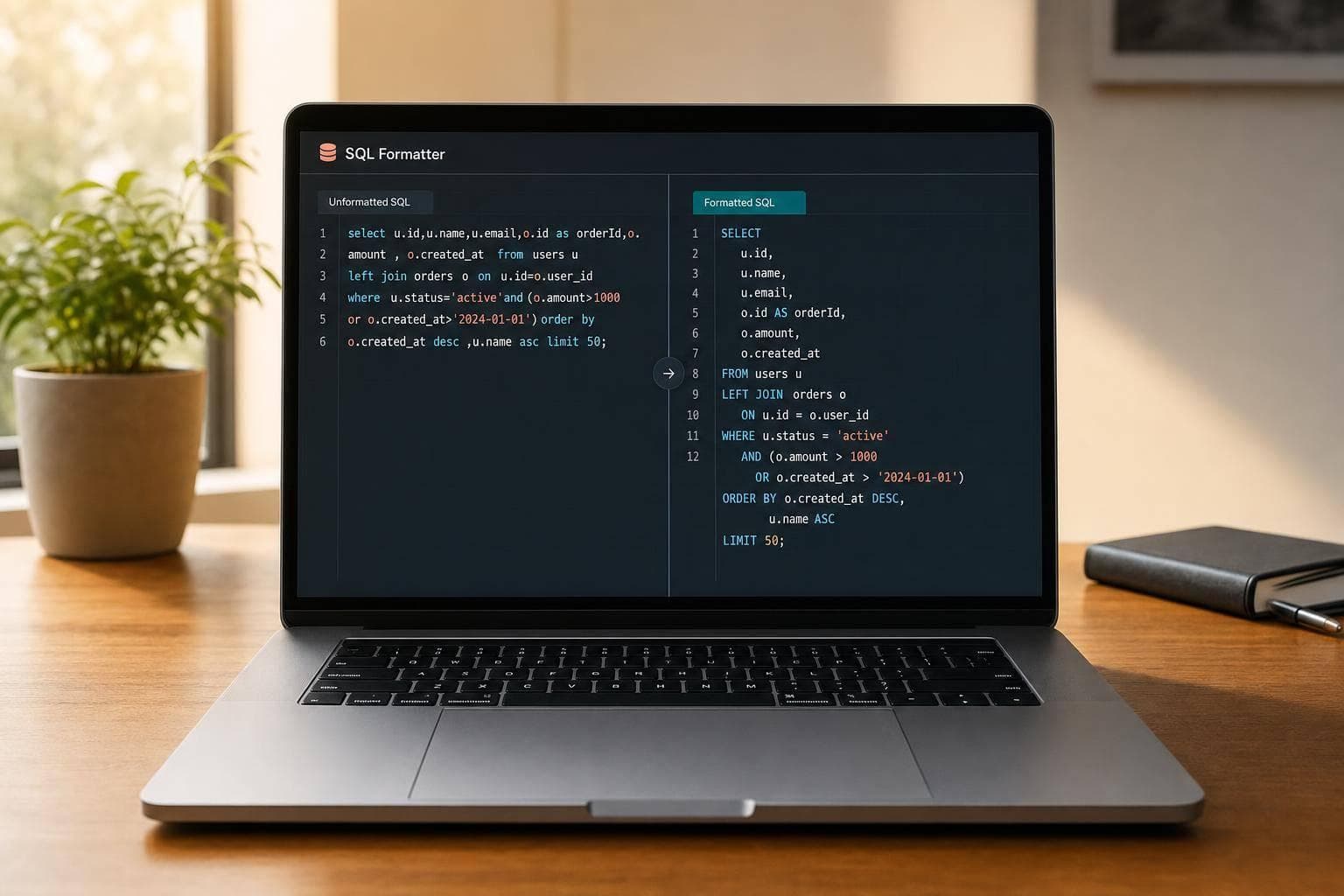
SQL Formatter
Paste messy SQL and format it instantly in your browser with readable spacing, keyword casing, and practical query styling options.

Git Workflows for Data Teams
Use one Git branch model, short-lived branches with reviews and CI, map Dev/Stage/Prod, and keep notebooks and large files out of Git.

Complete Guide to Data Engineering & Azure Databricks
Learn data engineering basics, ETL steps, Azure Databricks, Spark clusters, notebooks, jobs, and batch vs real-time data processing.

Top Tools for Data Lakehouse and Data Warehouse
Choose a lakehouse for unified SQL, ML, and streaming - use open formats and governance to avoid lock-in and control costs.

Caching with Redis: Best Practices for Engineers
Practical Redis caching guide: design keys, set TTLs with jitter, choose eviction policies, monitor, scale, and secure production caches.