
Ultimate Guide to Stream Processing Frameworks
Stream processing is all about analyzing and responding to data as it flows in real time, unlike batch processing, which processes data in chunks after collection. This guide covers the essentials of stream processing, including its principles, challenges, and the most popular frameworks like Apache Flink, Spark Structured Streaming, Kafka Streams, and AWS Kinesis.
Key Takeaways:
- Stream processing delivers immediate insights, crucial for tasks like fraud detection and IoT monitoring.
- Core features include low latency, stateful processing, and continuous execution.
- Challenges include handling late data, ensuring fault tolerance, and managing state efficiently.
Popular Frameworks:
- Apache Flink: Best for large-scale, stateful computations with low latency.
- Spark Structured Streaming: Ideal for teams already using Spark, though it uses micro-batches.
- Kafka Streams: Lightweight, integrates directly with Kafka, great for real-time microservices.
- AWS Kinesis: Fully managed, integrates seamlessly with AWS services.
Quick Comparison:
| Framework | Processing Model | Latency | Deployment | Best For |
|---|---|---|---|---|
| Apache Flink | Continuous | Milliseconds | Separate Cluster | Complex event processing |
| Spark Streaming | Micro-batch | Seconds | Separate Cluster | Unified batch/stream workflows |
| Kafka Streams | Continuous | Milliseconds | Embedded Library | Real-time Kafka integrations |
| AWS Kinesis | Continuous | Low | Managed Service | AWS-native ecosystems |
Choosing the right framework depends on your needs, infrastructure, and team expertise. Dive into the full guide for practical tips on scaling, managing time windows, and ensuring fault tolerance in your stream processing systems.
Stream Processing Frameworks Comparison: Apache Flink vs Spark vs Kafka Streams vs AWS Kinesis
Core Principles of Stream Processing
Key Features of Stream Processing
Stream processing revolves around three main capabilities: low latency, stateful processing, and continuous execution.
Low latency ensures results are delivered almost immediately - within milliseconds or seconds. For example, in the case of a fraudulent credit card transaction, the system must detect and flag the issue before the purchase is completed, not hours later during a batch process.
Stateful processing allows the system to retain context across multiple events. This is crucial for tasks like aggregations, counts, or joins. Without state, it would be impossible to calculate something like a user's average session duration or identify when a sensor reading suddenly deviates from its usual pattern.
The third critical feature is continuous execution. Unlike batch jobs that start, process a dataset, and stop, stream processors operate continuously, running 24/7. These systems can adjust resources dynamically based on the flow of data throughout the day. Continuous execution also supports incremental processing, where the system tracks previously processed data and only acts on new inputs, avoiding the inefficiency of reprocessing entire datasets.
"Streaming is a type of data processing engine that is designed with infinite data sets in mind. Nothing more." - Tyler Akidau, Senior Staff Software Engineer, Google
These features form the backbone of stream processing and set the stage for understanding the differences between event time and processing time.
Event Time vs. Processing Time
Event time refers to when an event actually occurred - whether it’s a user clicking a button, a sensor recording a temperature, or a stock trade being executed. On the other hand, processing time is when the system registers that data. Ideally, these two times align, but network delays or system outages can create discrepancies, ranging from milliseconds to days.
This distinction is critical because processing time is non-deterministic. Reprocessing the same data stream might yield different results since the system clock will reflect different timestamps. Event time, however, ensures consistent results, making it the preferred choice for applications like financial transactions or business analytics where precision is essential.
One challenge here is out-of-order data. Events don’t always arrive in the sequence they happened. For instance, a mobile app might store data while offline and upload it later when connectivity is restored. To address this, stream processors use watermarks, which act as markers indicating that "all events up to time t have probably arrived". This introduces a tradeoff: aggressive watermarks reduce latency but risk missing some data, while conservative watermarks ensure completeness but slow down processing.
Managing these time semantics is key to handling late-arriving data and ensuring accurate results.
Common Challenges in Stream Processing
Stream processing comes with its own set of challenges, particularly around managing state and time effectively.
Handling late and out-of-order data is one of the biggest hurdles. Network delays, device buffering, and the nature of distributed systems mean events rarely arrive in perfect order. Frameworks address this by using grace periods, which balance the tradeoff between latency and completeness. A longer grace period ensures more complete data but increases delay, while shorter periods prioritize speed at the risk of missing some events.
Processing guarantees are another critical aspect. These determine how the system handles failures and whether data can be lost or duplicated.
- Exactly-once processing ensures that each record is processed and impacts results precisely once. This is essential for applications like billing or financial systems where errors can have serious consequences.
- At-least-once processing, while not as strict, ensures no data is lost but may result in duplicate records. This is acceptable in scenarios like log monitoring, where occasional duplicates are less problematic.
"Strong consistency is required for exactly-once processing, which is required for correctness, which is a requirement for any system that's going to have a chance at meeting or exceeding the capabilities of batch systems." - Tyler Akidau, Senior Staff Software Engineer, Google
Finally, state management becomes increasingly complex as systems scale. Stateful operations such as joins and aggregations depend on maintaining context across millions of events. To handle this, systems rely on fault-tolerant local state stores, which use persistent key-value stores or in-memory structures that can recover data via changelogs or checkpoints if a node fails. Scaling horizontally further complicates this, as state must be distributed across multiple processing units while maintaining consistency.
These challenges highlight the intricate balancing act required to ensure stream processing systems are both efficient and reliable at scale.
sbb-itb-61a6e59
How to Process Streaming Data: A Quick Guide
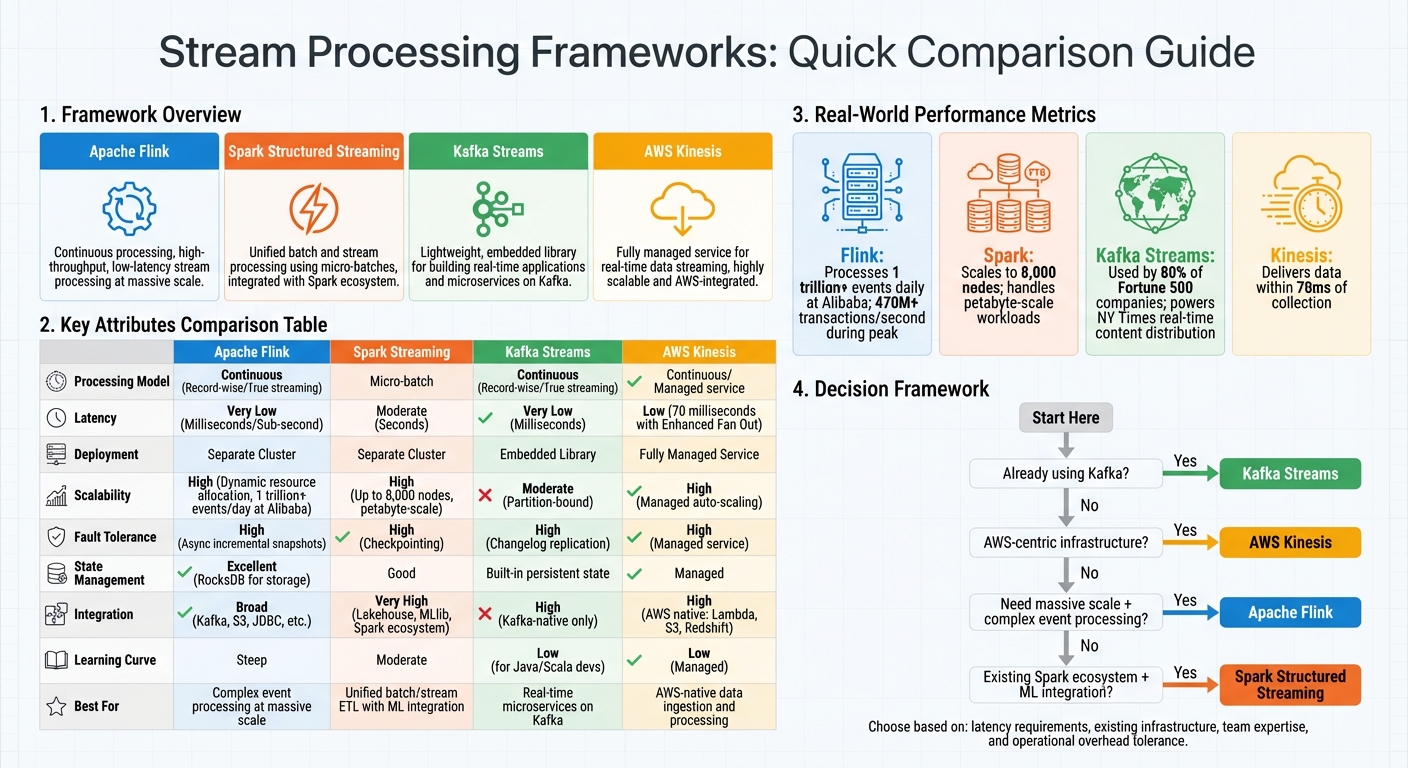
Popular Stream Processing Frameworks
When it comes to stream processing, several frameworks stand out for their unique architectures and capabilities. Let’s take a closer look at some of the most widely used options.
Apache Flink processes data continuously, handling one record at a time instead of using batches. This approach makes it particularly effective for stateful computations, leveraging tools like RocksDB for storage. Flink is known for its sub-second latency, achieved through asynchronous incremental snapshots. Its scalability is impressive - Alibaba, for instance, uses Flink to process over 1 trillion events daily and manage more than 470 million transactions per second during peak shopping events.
Apache Spark Streaming employs a micro-batching model, breaking live data into small batches for processing. While this results in latency measured in seconds, it integrates seamlessly with the larger Spark ecosystem. This includes tools like MLlib for machine learning and support for modern data formats like lakehouses. Spark can scale to clusters with up to 8,000 nodes and handle petabyte-scale workloads. However, the original Spark Streaming (DStreams) is now considered outdated, and Spark Structured Streaming is recommended for building new pipelines.
Apache Kafka Streams takes a different approach by operating as a lightweight client library embedded within your application, rather than requiring a separate processing cluster. It processes data continuously, directly from Kafka topics, making it ideal for real-time use cases. For example, The New York Times uses Kafka Streams to distribute content in real time, while Pinterest relies on it for predictive budgeting in its ad infrastructure. Rabobank also uses Kafka Streams to power "Rabo Alerts", which notify customers of financial events instantly. This framework is a great fit for microservices architectures where minimizing operational overhead is essential.
AWS Kinesis is a fully managed service designed for real-time data ingestion and processing, with tight integration into the AWS ecosystem. The Kinesis suite includes Data Streams for storage, Data Firehose for loading data into lakes and warehouses, and a Managed Service for Apache Flink for stream processing. It can process and deliver data to analytics applications within 70 milliseconds of collection. With its managed nature, Kinesis is an attractive option for teams fully embedded in AWS, offering seamless integration with services like Lambda, S3, and Redshift.
| Framework | Processing Model | Latency | Deployment | Best For |
|---|---|---|---|---|
| Apache Flink | Continuous (One at a time) | Very Low (Milliseconds) | Separate Cluster | Complex event processing at massive scale |
| Spark Streaming | Micro-batch | Moderate (Seconds) | Separate Cluster | Unified batch/stream ETL with ML integration |
| Kafka Streams | Continuous (One at a time) | Very Low (Milliseconds) | Embedded Library | Real-time microservices on Kafka |
| AWS Kinesis | Continuous | Low | Managed Service | AWS-native data ingestion and processing |
Next, we’ll dive into how to compare these frameworks and choose the one that best suits your specific needs.
How to Choose the Right Stream Processing Framework
Framework Comparison
Selecting the right streaming framework involves weighing factors like latency, scalability, and operational complexity. The goal is to find the best fit for your specific needs and trade-offs.
Here’s a breakdown of how popular frameworks handle key features like latency, fault tolerance, and integration:
| Feature | Apache Flink | Apache Spark Streaming | Apache Kafka Streams | AWS Kinesis |
|---|---|---|---|---|
| Processing Model | Record-wise (True streaming) | Micro-batch | Record-wise (True streaming) | Managed service supporting Flink or SQL-based queries |
| Scalability | High (Dynamic resource allocation) | High (Cluster-based) | Moderate (Partition-bound) | High (Managed auto-scaling) |
| Fault Tolerance | High (Async snapshots) | High (Checkpointing) | High (Changelog replication) | High (Managed service) |
| Integration | Broad (Kafka, S3, JDBC, etc.) | Very High (Lakehouse, Spark ecosystem) | High (Kafka-native only) | High (AWS-native only) |
| Latency | Lowest (Millisecond) | Higher (Micro-batch intervals) | Low (Millisecond) | Low (Millisecond) |
| Learning Curve | Steep | Moderate | Low (for Java/Scala devs) | Low (Managed) |
Latency is often a key concern. If you need real-time, event-by-event processing, Flink and Kafka Streams are ideal, delivering millisecond-level responsiveness. Spark, with its micro-batching model, introduces slightly higher delays. AWS Kinesis, particularly with Enhanced Fan Out, can achieve latencies as low as 70 milliseconds.
For state management, frameworks like Flink and Kafka Streams shine, offering built-in persistent state that supports complex analytics, such as fraud detection or windowed aggregations.
Scalability also varies. Kafka Streams is limited by Kafka's partition count, which restricts workload distribution. In contrast, Flink's dynamic resource allocation has been tested at massive scales, such as processing over 1 trillion events daily at Alibaba. Spark scales by adding cluster nodes but lacks the flexibility of dynamic allocation for streaming workloads.
What to Consider When Choosing a Framework
Your current infrastructure should play a big role in your decision. For instance, if your organization already uses Apache Kafka (as 80% of Fortune 500 companies do), Kafka Streams might be the simplest option. It integrates directly with Kafka, running as a lightweight library within your application. Similarly, AWS-centric teams can benefit from Kinesis to streamline integration with other AWS services. Spark users may find Structured Streaming appealing since it allows them to build on existing codebases and team expertise.
Team expertise is another critical factor. Frameworks like Spark and Flink support Java, Scala, and Python, while Kafka Streams is primarily designed for JVM languages. If your team is more comfortable with SQL, frameworks that offer native SQL support are worth exploring. For AI/ML pipelines, Python-friendly options like Bytewax or Faust might be a better match.
Operational overhead should not be overlooked. Managed services like AWS Kinesis and Google Cloud Dataflow reduce infrastructure complexity but can lead to vendor lock-in and higher costs. On the other hand, self-managed frameworks like Flink and Spark provide greater control but require specialized expertise for scaling and troubleshooting.
"Building a distributed streaming platform... is extremely challenging, where failure is not a question of 'if' but 'when'" - Sumit Pal, former Gartner VP Research Analyst.
For startups or smaller teams, lightweight frameworks like Kafka Streams are a practical choice, minimizing infrastructure demands. For large-scale, mission-critical operations, Apache Flink stands out with its robust state management and exactly-once processing guarantees. If your organization already uses Spark for batch processing, Structured Streaming offers a unified solution - just ensure its micro-batch latency aligns with your requirements.
Best Practices for Stream Processing
Here’s a closer look at how to effectively deploy, fine-tune, and scale your stream processing applications.
Designing for Scalability
Scalability starts with data partitioning. In Kafka Streams, the number of partitions in your input topic determines the maximum level of parallelism. For example, if you have 10 partitions, you can only run up to 10 parallel tasks. Planning your partitioning strategy with future growth in mind is key.
For workloads limited by network, memory, or disk, horizontal scaling - adding more machines - is the way to go. On the other hand, vertical scaling - adding more resources to your current machines - is better for CPU-heavy tasks. If you choose vertical scaling in Kafka Streams, adjust the num.stream.threads parameter to align with your machine's CPU cores.
"Scaling a Kafka Streams application effectively involves a multi-faceted approach that encompasses architectural design, configuration tuning, and diligent monitoring." - Bijoy Choudhury, Solutions Engineering Leader, Confluent
For stateful applications, consider distributing state stores alongside data partitions. This ensures each task handles only a portion of the total state. Keep an eye on consumer lag - if your application struggles to keep up with incoming data, it's time to scale. It’s also a good idea to configure standby replicas to reduce downtime during failures or rebalancing. However, note that adding more instances than your partition count will leave the extra ones idle.
Once your architecture is scalable, managing time windows effectively becomes your next priority.
Time Windows and Watermarks
To handle late-arriving data, rely on event time for consistent and predictable results.
Watermarks are progress markers in your stream that declare, "all events up to time t have arrived." They help close windows and trigger result generation. Typically, you set watermarks by subtracting a slack interval - like 30 seconds - from the latest observed timestamp to account for delays.
"A watermark means, 'I have seen all records until this point in time'." - Confluent Documentation
Define an allowed lateness period to keep windows open for late data. Records arriving after this period can be redirected to a side output for further auditing or processing. In Flink SQL, you can specify your watermark strategy with a WATERMARK clause, such as WATERMARK FOR ts AS ts - INTERVAL '5' SECOND.
Choose the right window type for your needs:
- Tumbling windows: Fixed-size windows for reports like hourly sales.
- Sliding windows: Overlapping windows for metrics like moving averages.
- Session windows: Dynamic windows where gaps in activity define boundaries.
Ensuring Fault Tolerance
Fault tolerance is essential for reliable stream processing.
Checkpointing protects your application's state during failures. Regularly save state - including offsets and internal aggregations - to durable storage like S3 or HDFS. This ensures your system can resume from the last stable state after a crash.
Use standby replicas and replicated changelog topics to speed up state recovery following failures.
For large-scale systems managing millions of keys, consider RocksDB as your state store. RocksDB moves state out of the JVM heap, reducing memory pressure and avoiding garbage collection delays. To prevent unbounded state growth, use watermarks or TTL (time-to-live) configurations for automatic state cleanup.
When re-processing, ensure your sink can handle duplicate writes without issues. This is critical for maintaining data integrity in production environments. Finally, name your streaming queries explicitly using queryName to make them easier to monitor and manage.
Conclusion
Key Takeaways
Stream processing has become a crucial tool in staying competitive. Companies that can act on insights in real time often outpace their rivals - quick reaction times are what drive impactful decisions. This guide explored the basics of stream processing, explaining how it processes data incrementally as it arrives and highlighting various frameworks, from lightweight options like Kafka Streams to powerful engines like Apache Flink.
Selecting the right framework hinges on your unique needs, such as latency tolerance, scalability requirements, existing infrastructure, and your team's skill set. There's no universal solution. Whether you choose managed services like AWS Kinesis or open-source tools you manage yourself, the goal is to align your choice with your organization's broader ecosystem. Operational success depends on adopting best practices, like designing for idempotency to avoid duplicate data, using checkpointing for fault tolerance, enforcing schema registries to maintain data integrity, and monitoring event lag to maintain real-time performance.
Next Steps for Data Professionals
To build on these concepts, focus on mastering advanced skills like stateful processing, event-time handling, and exactly-once semantics. These areas not only present challenges but also open up opportunities for innovation. As businesses increasingly rely on real-time systems, professionals skilled in streaming are essential for creating solutions like fraud detection, IoT monitoring, and dynamic pricing.
Dive deeper into advanced topics such as windowing operations, state management, and watermarking. Hands-on experience is key - practice beats theory every time. For structured learning, check out DataExpert.io Academy (https://dataexpert.io), which offers targeted boot camps in data engineering. These programs include practical training, capstone projects, and exposure to tools like Databricks and AWS.
The move from batch to stream processing is picking up speed, and the value of data often diminishes within seconds of its creation. Developing the ability to process and act on data in real time could be a game-changer for your career.
FAQs
When should I use event time instead of processing time?
When precise time-based operations matter - like in time series analysis, windowed aggregations, or handling late or out-of-order data - event time is the way to go. It uses the original timestamp of an event, ensuring your results align with when the events actually happened. This approach is especially important for tasks like calculating averages over defined periods or reprocessing historical data, where maintaining temporal accuracy and data integrity is non-negotiable.
How do watermarks handle late or out-of-order events?
Watermarks play a crucial role in stream processing frameworks by helping manage late or out-of-order events. Essentially, a watermark represents a specific point in time, signaling that no events earlier than this timestamp are expected to arrive. This mechanism enables systems to handle late data within a predefined threshold, ensuring reliable time-based operations like windowing and aggregation.
When the watermark progresses past a given time window, the system triggers computations for that window. Any data arriving after this point is discarded, striking a balance between maintaining accuracy and ensuring efficient processing.
Which framework fits my use case: Flink, Spark, Kafka Streams, or Kinesis?
The best stream processing framework hinges on your specific needs, like latency, scalability, and integration. Apache Flink shines in scenarios requiring low latency and high throughput, especially with event-time processing. Apache Spark Structured Streaming is better suited for handling massive data volumes, though it comes with slightly higher latency. If you're working with event-driven and low-latency requirements, Kafka Streams (for embedded use) and Amazon Kinesis (as a managed cloud service) are excellent choices. Align your framework choice with your operational priorities.