
Soda vs. Great Expectations: Data Quality Tools
Which tool is better for your team? It depends on your needs. Soda and Great Expectations both ensure data quality but approach it differently. Soda is SQL/YAML-based, easy to set up, and great for real-time monitoring. Great Expectations is Python-based, flexible, and ideal for complex validations and documentation.
Key Takeaways:
- Soda: Quick to implement, focuses on production monitoring with real-time alerts, integrates easily with SQL-heavy workflows, making it a favorite for those preparing for analytics engineering interviews.
- Great Expectations: Best for advanced, Python-driven validation logic, detailed data documentation, and development workflows.
Quick Comparison:
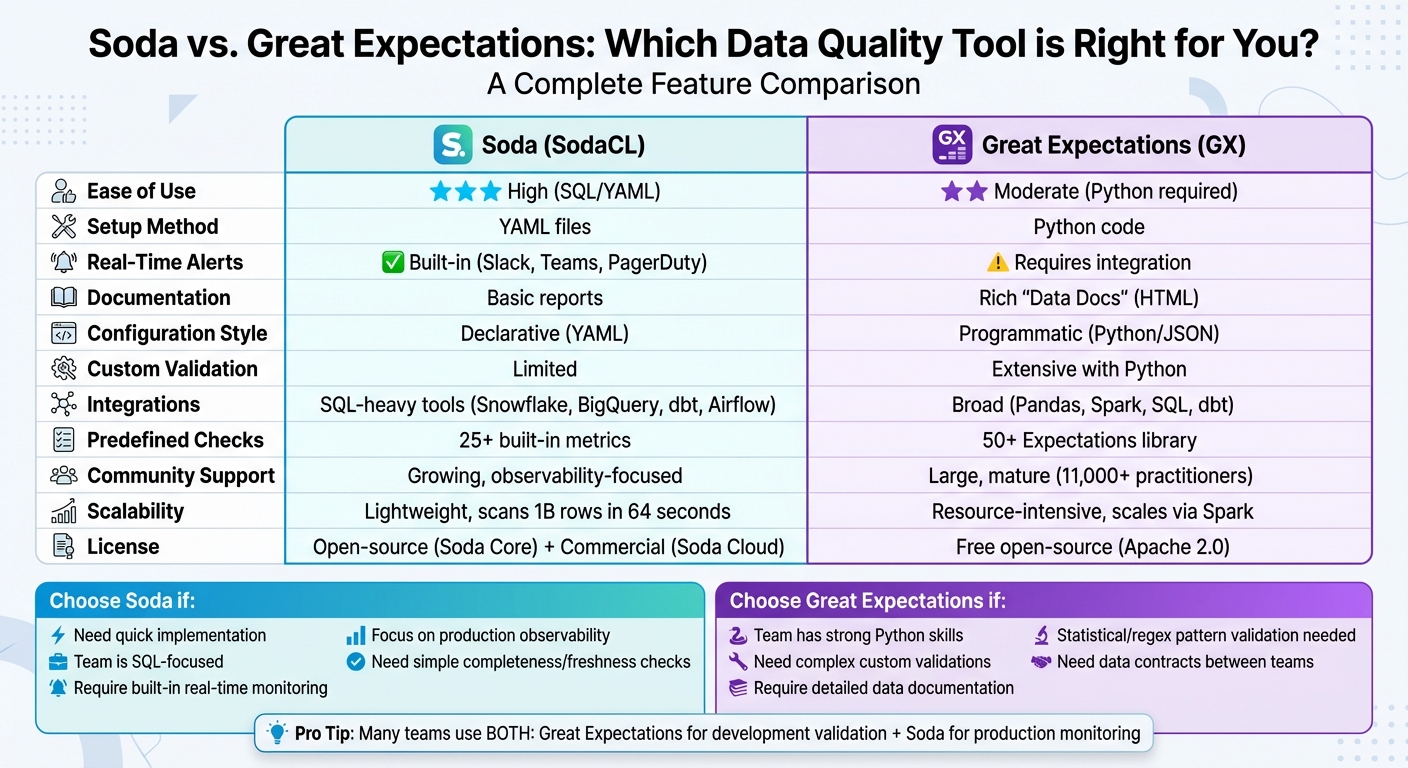
| Feature | Soda (SodaCL) | Great Expectations (GX) |
|---|---|---|
| Ease of Use | High (SQL/YAML) | Moderate (Python required) |
| Setup | YAML files | Python code |
| Real-Time Alerts | Built-in | Requires integration |
| Documentation | Basic reports | Rich, detailed "Data Docs" |
| Integrations | SQL-heavy tools | Broad (Pandas, Spark, dbt) |
| Custom Validation | Limited | Extensive with Python |
Pro Tip: Many teams combine both - Soda for production monitoring and Great Expectations for development validation.
Soda vs Great Expectations: Complete Feature Comparison for Data Quality Tools
What's the Right Data Quality Tool for You? Top Data Quality Tools Reviewed and Explained!
sbb-itb-61a6e59
Soda Features
Soda offers a YAML-based declarative framework for quick and user-friendly data quality checks through SodaCL. Its standout feature, SodaCL (Soda Check Language), allows teams to define data quality rules in plain language. If you’re familiar with writing a SQL WHERE clause, you’re already equipped to use SodaCL effectively. Let’s dive into the key features that make Soda a powerful tool for managing data quality. Many professionals refine these skills through data engineering and AI training programs.
Real-Time Monitoring and Alerts
With Soda 4.0, real-time anomaly detection takes center stage. Powered by AI, it continuously monitors production data, identifying unexpected changes while reducing false positives by 70% compared to Facebook Prophet. Impressively, it can scan 1 billion rows in just 64 seconds. When issues arise, Soda sends instant alerts to platforms like Slack, Microsoft Teams, PagerDuty, or ServiceNow, helping teams quickly pinpoint and address problems. Gu Xie, Head of Data Engineering, highlighted the value of this feature:
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in.
Simple Setup and Configuration
Setting up Soda is straightforward and requires just two YAML files: one for connecting data sources and another for defining checks (e.g., row_count > 0 or missing_count(column) = 0). Installation is as simple as running a pip command (e.g., pip install soda-snowflake), and scans can be executed using an intuitive CLI command (soda scan -d [datasource] -c configuration.yml checks.yml). The checks are designed to be easy to write, making them accessible to both engineers and business users. Sid Srivastava, Director of Data Governance, Quality and MLOps, shared:
We don't want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what's happening, and that's what Soda is enabling right now.
Integration with Data Stack Tools
Soda fits seamlessly into modern data workflows, integrating with orchestration tools like Airflow, Dagster, Prefect, and Azure Data Factory. It also works with transformation tools such as dbt and connects to popular data warehouses like Snowflake, BigQuery, Redshift, and Databricks. Additionally, Soda supports data catalogs, including Atlan, Alation, and Collibra, and integrates into CI/CD pipelines (e.g., GitHub Actions) to surface quality metrics and catch issues before they hit production. Sutaraj Dutta, Data Engineering Manager, described the integration experience:
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Great Expectations Features
Great Expectations (GX) offers a Python-driven approach to ensuring data quality. Instead of relying on YAML configurations, it uses "Expectations" - readable Python methods like expect_column_values_to_be_between, which act as unit tests for your data. This programmatic design gives engineers the ability to handle anything from basic null checks to intricate statistical validations, all while tapping into Python's extensive ecosystem. This approach highlights GX's emphasis on flexibility, traceability, and a supportive developer community.
Data Validation and Documentation
One of GX's standout features is its ability to turn validation rules into actionable insights. It automatically converts these rules into HTML reports called Data Docs, which are continuously updated. These reports act as a shared data contract, bridging the gap between technical teams and business stakeholders. By running validations through Checkpoints - bundles of Expectation Suites tied to specific data batches - GX can trigger automated actions, such as sending Slack notifications or updating documentation. Unlike Soda, which relies on YAML configurations, GX integrates validation and documentation dynamically through code.
Albert Chavez, a Data Engineer at Moody's Analytics, shared his thoughts:
I love Great Expectations for making data quality more effortless for our team – plus, their documentation and community are beyond excellent.
Customization Options
Python's versatility makes GX highly customizable for unique data requirements. While GX offers over 50 built-in expectations, users can create custom Python methods to address specific needs - whether it's validating statistical distributions, complex regex patterns, or business rules that span multiple datasets. The framework also supports interactive development in Jupyter Notebooks, enabling users to prototype and refine their custom expectations before deploying them into production pipelines. Hodman Murad from The Data Letter noted:
GX's programmatic nature makes this possible. You can leverage the full power of Python to create highly specific Expectations.
Open-Source Community
With a global community of over 11,000 data practitioners, Great Expectations has become a widely adopted tool. As of September 2023, its GitHub repository boasts 9,100 stars, 1,400 forks, and contributions from 365 developers. The community also curates an Expectations Gallery with over 300 pre-defined assertions and actively develops integrations for tools like dbt, Airflow, and Dagster. Aleksei Chumagin, Head of QA at Provectus, highlighted the community's impact:
Great Expectations is a powerful tool that helps us along all Data QA stages, comes with many integrations and can be quickly built into your pipelines.
GX Core is free and open-source, licensed under Apache 2.0. Support is readily available through public Slack channels, GitHub Discussions, and detailed documentation.
Side-by-Side Comparison
When choosing between Soda and Great Expectations, the right pick often hinges on your team's workflow and project requirements. Soda leans on a declarative, SQL-friendly approach using YAML files, while Great Expectations takes a programmatic, Python-first route.
The learning curve is another key distinction. Soda's SQL/YAML setup is approachable for anyone familiar with writing a SQL WHERE clause. In contrast, Great Expectations demands Python knowledge and familiarity with concepts like Data Contexts and Batch Requests. As Rajas Abhyankar aptly put it:
Data quality is the unsung hero of reliable analytics, AI models, and production reporting - and when it fails, no one forgets.
Feature Comparison Table
Here’s a quick breakdown of the core differences to help you decide:
| Feature | Soda (SodaCL / Core) | Great Expectations (GX) |
|---|---|---|
| Ease of Use | High (SQL/YAML based) | Moderate to Low (Python required) |
| Configuration | Declarative (YAML) | Programmatic (Python/JSON) |
| Real-time Alerting | Built-in via Soda Cloud (Slack, Teams) | Requires external integration/orchestrator |
| Documentation | Functional pass/fail reports | Rich, human-readable "Data Docs" |
| Integrations | Broad (Snowflake, BigQuery, dbt, Airflow) | Broad (Pandas, Spark, SQL, dbt) |
| Predefined Checks | 25+ built-in metrics | Extensive library of "Expectations" |
| Scalability | Lightweight; efficient for scanning | Can be resource-intensive; scales via Spark |
| Community Support | Growing; strong focus on observability | Large, mature open-source community (11,000+ practitioners) |
This comparison highlights how each tool fits into different stages of a data workflow, bridging validation during development and observability in production.
Great Expectations stands out for its robust documentation and validation capabilities. Its "Data Docs" create HTML reports that act as a data contract between technical teams and business stakeholders. Soda, on the other hand, emphasizes production monitoring and observability, offering built-in alerting integrations with tools like Slack, Microsoft Teams, and PagerDuty. It's common for teams to adopt a hybrid approach - using Great Expectations for complex validation during development and CI/CD pipelines, while relying on Soda for continuous monitoring in production.
Both tools are available as free open-source versions: Soda Core and GX OSS. Soda also offers commercial products like Soda Cloud and Soda Agent, which add features like observability, alerting, and a managed UI. Great Expectations remains primarily open-source, with support available through Slack, GitHub Discussions, and detailed documentation.
When to Use Each Tool
When to Choose Soda
Go with Soda when you need to roll out a data quality framework fast and your team is comfortable working with SQL. If Python feels like overkill or adds unnecessary complexity, Soda's YAML-based setup can have you defining checks in just minutes. As Hodman Murad puts it:
Choose Soda Core if: You need to get a data quality framework up and running yesterday.
Soda shines in production monitoring, especially when real-time alerts are crucial. It efficiently handles essential metrics like freshness, volume, and completeness, helping teams spot problems before they cascade into larger issues. Its SQL pushdown approach, which processes checks directly in your data warehouse, is perfect for SQL-heavy environments like Snowflake, BigQuery, or Redshift.
However, if your project requires more advanced validation logic, you might want to consider a different tool.
When to Choose Great Expectations
Great Expectations is the go-to choice for scenarios that call for advanced customization and complex validations, such as regex checks, statistical monitoring, or multi-dataset comparisons. Its Python-driven nature offers the flexibility needed for intricate validation tasks. Hodman Murad explains:
Choose Great Expectations if: You have complex validation logic that requires the full expressiveness of Python.
One of its standout features is the ability to generate detailed Data Docs, which help align technical teams and business stakeholders. This makes it a strong option for teams with solid Python skills who are building robust data contracts for development workflows and CI/CD pipelines. Tom Preece, Lead Data Scientist at Peak, highlights its benefits:
Great Expectations allows us to quickly set up data checks so that we can be confident that the input data is consistent.
The decision ultimately boils down to what your project needs - speed and simplicity or advanced, customizable validation capabilities.
Implementation Best Practices
Planning Your Data Quality Approach
Start by identifying your key datasets and mapping out high-priority business rules that align with critical KPIs. There's no need to test everything right away. Instead, establish an initial baseline of checks. Focus on common issues like completeness (null values), uniqueness (duplicates), range validity, and schema conformity. These foundational checks can help you catch most problems early on before they grow into bigger challenges.
When selecting tools, consider your team's expertise or entry-level data engineering training and the complexity of your project. For example, if you need advanced validation logic - like statistical analyses or regex patterns - Great Expectations provides the Python-based flexibility to create tailored solutions.
Adding Tools to Your Data Pipeline
Once you've outlined your data quality priorities, it's time to integrate these checks into your data pipeline. Tools like Soda and Great Expectations are designed to work seamlessly with modern data stacks.
-
Soda: Install the appropriate package for your data source (e.g.,
pip install soda-postgres), configure your connection in aconfiguration.ymlfile, and write checks using SodaCL. You can execute scans via the command line or orchestrators like Airflow using Airflow'sPythonVirtualenvOperator. -
Great Expectations: This tool requires a bit more setup. Use the
initcommand to create your project structure, define Expectations programmatically in Python (often through Jupyter notebooks), and establish Checkpoints to run these Expectations on data batches. Great Expectations also generates Data Docs, which provide a clear visualization of your results.
For teams using dbt, both tools offer integrations: soda-dbt for Soda and dbt-expectations for Great Expectations. These allow you to run checks as native dbt tests. Incorporate scans at critical stages - after data ingestion (raw data), after initial transformations, and just before pushing data to reporting tools. By using orchestrators like Airflow, you can even halt pipelines if critical checks fail, ensuring bad data never reaches your dashboards.
After setting up these tools, focus on refining and optimizing your processes over time.
Improving and Scaling Over Time
To scale effectively, combine validation-as-code (integrated into your CI/CD pipelines) with ongoing production monitoring. For instance, Soda offers real-time alerts that can notify your team of issues immediately. Store your checks in Git for version control, and connect automated alerts (via Slack or Teams) to detailed remediation steps with assigned owners. This setup can significantly reduce the time it takes to resolve issues.
To avoid unnecessary strain on your system, skip full-table scans. Instead, use sampling, incremental checks, or monitor specific metrics. By tracking test results over time, you can distinguish between temporary spikes and gradual changes in the data. In Soda Cloud, you can also organize datasets by tagging them (e.g., raw, transformed, reporting) to streamline management and filtering.
Finally, aim for flexibility in your checks. Statistical validations and defined tolerances are often more effective than rigid rules, as they can adapt to normal data fluctuations without triggering false alarms.
Conclusion
Soda and Great Expectations tackle data quality in distinct ways, each offering specific strengths depending on your needs. Soda focuses on speed and ease of use with its YAML-based approach and real-time monitoring, making it ideal for teams that need quick, straightforward setups. On the other hand, Great Expectations caters to those requiring more advanced validation and detailed documentation, particularly through its Python-powered customization.
For teams with data analysts who need to implement checks quickly, Soda's approachable setup is a practical choice. Meanwhile, if your team includes skilled Python developers working on complex validations or creating detailed data contracts, Great Expectations provides the depth and flexibility needed.
Interestingly, many organizations find value in combining both tools - using Great Expectations for development validations and Soda for real-time production monitoring. Ultimately, the best choice depends on your team's expertise and the specific demands of your project. By aligning the tool with your workflow and priorities, you can ensure a smoother path to maintaining high data quality.
FAQs
Can I use Soda and Great Expectations together?
Yes, you can absolutely use Soda and Great Expectations together - they're often seen as complementary tools. Many experts point out that integrating these two can provide deeper insights into data quality across an organization. By combining their strengths, you can simplify data validation and monitoring processes, leading to more efficient and effective results.
Where should data quality checks run in my pipeline?
Data quality checks are essential at various points in your pipeline to identify problems as early as possible. These critical stages include after data extraction, during transformation, and before loading into the target system. Tools such as Soda can easily integrate with orchestration environments, automating checks to spot issues like schema changes, data drift, or quality drops. This helps maintain strong data integrity throughout the entire pipeline process.
How do I avoid slow full-table scans and noisy alerts?
To avoid sluggish full-table scans and reduce unnecessary alerts, focus on fine-tuning your data quality checks for both efficiency and accuracy. Leverage configurable checks with well-thought-out defaults to strike the right balance between thoroughness and performance. Incorporate anomaly detection methods to identify subtle issues early on while minimizing the risk of excessive, irrelevant alerts. By carefully adjusting configurations and detection strategies, you can achieve dependable, cost-efficient monitoring without overwhelming your system or creating avoidable noise.