
7 Essential Skills Every Data Engineer Needs
To excel as a data engineer in 2026, you need a mix of technical expertise and problem-solving abilities. With the rapid growth of data-driven systems, here are the seven must-have skills:
- SQL Mastery: The backbone of data manipulation, SQL is critical for querying, transforming, and optimizing data across platforms like Snowflake, BigQuery, and PostgreSQL.
- Python Programming: Essential for automation, custom data connectors, and managing workflows. Libraries like Pandas, PySpark, and SQLAlchemy are key.
- Data Modeling: Designing efficient schemas and structures ensures scalable, high-performance systems. Techniques like normalization, SCD, and tools like dbt are vital.
- ETL/ELT Pipeline Design: Building reliable pipelines for data movement and transformation using tools like Airflow, Fivetran, and Dagster is crucial for modern workflows.
- Cloud Platform Expertise: Proficiency in AWS, Google Cloud, or Azure is necessary for managing storage, compute, and cost-effective architectures.
- Data Governance and Observability: Ensuring data quality, compliance, and monitoring with tools like Great Expectations, Monte Carlo, and Soda is critical for reliability.
- Problem-Solving and Communication: Debugging complex systems and translating technical details into business insights are key to collaborating across teams.
Quick Comparison
| Skill | Purpose | Tools/Platforms |
|---|---|---|
| SQL Mastery | Query and transform data | Snowflake, PostgreSQL, BigQuery |
| Python Programming | Automate and customize workflows | Pandas, PySpark, SQLAlchemy |
| Data Modeling | Design scalable data systems | dbt, Power BI, Snowflake |
| ETL/ELT Pipeline Design | Move and process data efficiently | Airflow, Dagster, Fivetran |
| Cloud Platform Expertise | Manage scalable infrastructure | AWS, Google Cloud, Azure |
| Data Governance | Ensure quality and compliance | Great Expectations, Monte Carlo, Soda |
| Problem-Solving | Debug and communicate effectively | Slack, Jira, Tableau |
These skills are the foundation for thriving in a field where demand continues to grow. By mastering these areas, you’ll be equipped to tackle modern data challenges and deliver impactful solutions.
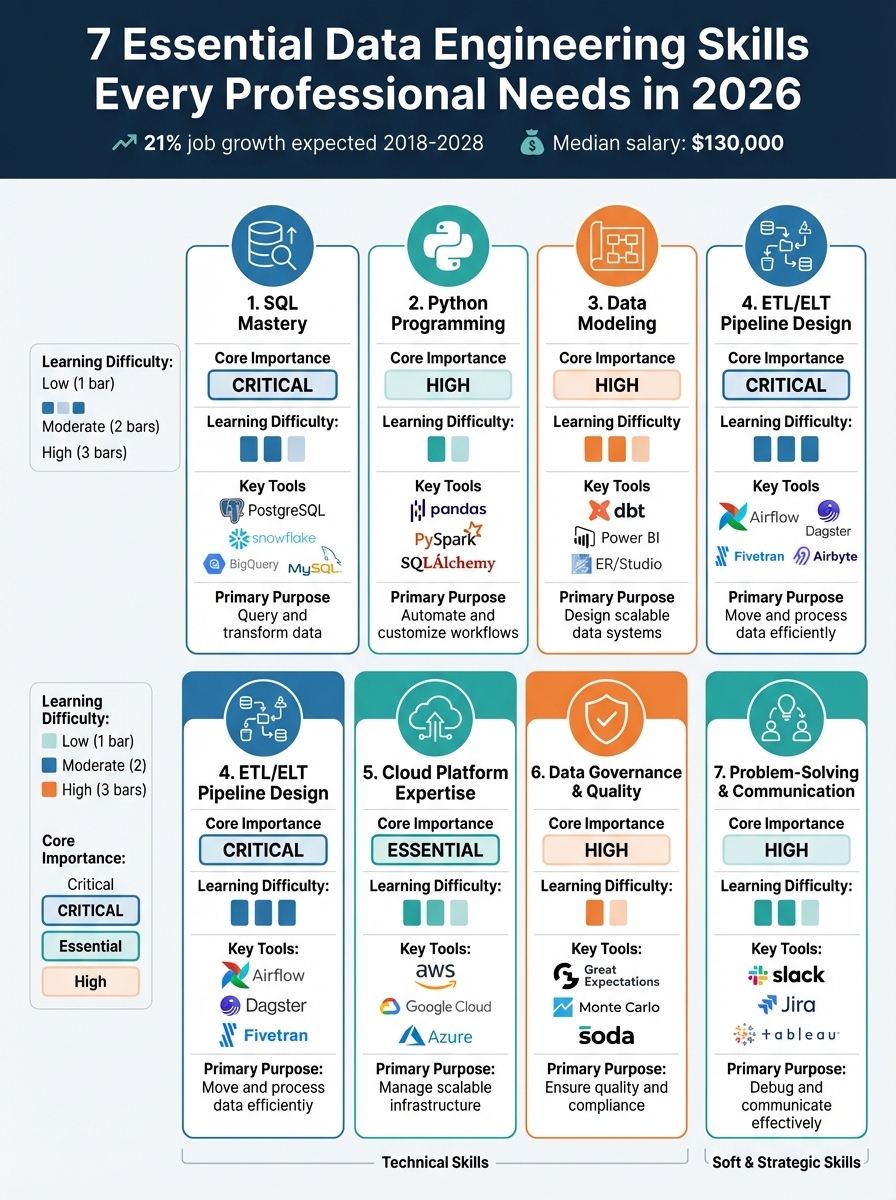
7 Essential Data Engineering Skills: Comparison of Importance, Difficulty, and Tools
1. SQL Mastery
Core Importance
SQL is the cornerstone of data engineering, acting as the go-to language for manipulating data across nearly all modern platforms. From traditional relational databases like PostgreSQL to cloud-based solutions such as Snowflake, BigQuery, and Redshift, SQL is everywhere. Joey Gault from dbt Labs puts it plainly:
"SQL proficiency remains non-negotiable, as it serves as the primary language for data manipulation across virtually all modern data platforms."
Data engineers rely on SQL daily to craft efficient queries, organize datasets for analysis, and diagnose performance issues. It’s how business requirements are turned into actionable insights. With the rise of the ELT (Extract, Load, Transform) model, SQL has become even more central. Transformations now happen directly within data warehouses, making SQL the backbone of this process. By diving deeper into advanced SQL techniques, engineers can not only enhance efficiency but also cut down on compute costs.
Learning Curve
To truly excel, engineers must go beyond the basics of SELECT statements. Mastery involves learning advanced features like window functions (great for calculations across related rows), common table expressions (CTEs) for breaking down complex logic, and recursive queries for navigating hierarchical data. Understanding the impact of data design choices - such as normalization versus denormalization - on workflows and query performance is what sets senior engineers apart from junior ones.
Modern data engineers also need to sharpen their skills in query optimization. This means deciphering execution plans, using indexing wisely, and refactoring queries to minimize compute costs in cloud environments. The ELT model has also made tools like dbt indispensable, requiring engineers to be proficient in modular, version-controlled SQL transformations.
Practical Applications
In day-to-day tasks, engineers often use anti-joins with constructs like NOT EXISTS or EXCEPT to find missing records between tables. They generate surrogate keys using UUIDs or hashes (e.g., GENERATE_UUID() in BigQuery) to ensure stable joins and deduplication in distributed systems. Managing data integrity during multi-step operations often involves transaction control commands like BEGIN, COMMIT, and ROLLBACK.
Performance tuning is another critical skill. For instance, selecting only the necessary columns instead of using SELECT * can significantly reduce data volume and save costs. Using CTEs instead of subqueries can improve code readability and maintainability. When working with window functions, adding tie-breakers in the ORDER BY clause ensures consistent results. These techniques not only solve immediate challenges but also prepare engineers for tackling more complex problems. SQL mastery forms the foundation for advanced data engineering, a theme that will be explored further in upcoming sections.
Relevant Tools or Platforms
| Platform Type | Common Tools | Primary Use Case |
|---|---|---|
| Cloud Data Warehouses | Snowflake, BigQuery, Redshift | Large-scale analytics and ELT transformations |
| Relational Databases | PostgreSQL, MySQL, SQL Server | Transactional systems and structured data storage |
| Transformation Tools | dbt (Data Build Tool) | Modular, version-controlled SQL transformations |
| NoSQL Databases | MongoDB, Cassandra | Managing unstructured data with flexible scaling |
Each platform comes with its own SQL dialect and optimization strategies. For example, PostgreSQL is known for its object-relational capabilities, while Snowflake offers columnar storage and auto-scaling features. Understanding these nuances allows engineers to write SQL that performs well across different environments.
2. Python Programming
Core Importance
Python is a cornerstone in the world of data engineering, appearing in about 70% of job postings for the field. Its versatility allows engineers to automate repetitive tasks, create custom data connectors, and manage workflows that go well beyond the limits of SQL. Known as a "glue language", Python seamlessly connects systems built in languages like Java or C++.
This language serves as a bridge between foundational data infrastructure and advanced applications such as machine learning and artificial intelligence. Data engineers rely on Python to pull data from REST APIs, integrate SaaS platforms, and process unstructured data. Tools like Apache Airflow and Databricks use Python to handle task scheduling and dependency management. These features make Python an essential tool for aligning traditional data operations with cutting-edge analytics.
Learning Curve
To get started, focus on mastering core libraries like Pandas for data manipulation, NumPy for numerical computations, and SQLAlchemy for database interactions. When working with datasets too large for a single machine, transitioning to PySpark for distributed processing is crucial. Following best practices like version control, CI/CD testing, and modular coding ensures that your pipelines are both reliable and maintainable. Writing modular functions - such as extract(), transform(), and load() - not only improves reusability but also simplifies debugging.
Practical Applications
Python is widely used to build ETL pipelines that extract, transform, and load data from various sources, including relational databases, NoSQL systems, CSV files, and JSON APIs. With specialized SDKs like boto3 for AWS, google-cloud-storage for GCP, and azure-storage-blob for Azure, data engineers can easily transfer data across cloud platforms. It also handles complex transformations that SQL can't manage. For example, Pandas is often used to clean messy data, standardize formats, and restructure datasets before loading them into data warehouses. Python scripts can be automated using tools like cron or integrated with orchestration platforms such as Airflow and Prefect. To avoid issues like duplicate records, idempotent scripts are commonly implemented.
Relevant Tools or Platforms
| Category | Key Python Libraries | Primary Use Case |
|---|---|---|
| Data Manipulation | Pandas, NumPy | Cleaning, transforming, and analyzing structured data |
| Big Data Processing | PySpark | Distributed processing of massive datasets |
| Database Connectivity | SQLAlchemy, psycopg2, pymongo | Connecting to relational and NoSQL databases |
| Workflow Orchestration | Apache Airflow, Dagster, Prefect | Managing task dependencies, retries, and scheduling |
| Cloud Integration | boto3, google-cloud-storage, azure-storage-blob | Moving data across AWS, GCP, and Azure platforms |
| Data Quality | Great Expectations | Automated validation and testing of data pipelines |
3. Data Modeling and Schema Design
Core Importance
Data modeling is the backbone of any data system, defining how information is structured, stored, and interconnected within databases and warehouses. It’s not just about organizing data - it’s about creating a system that performs efficiently and scales as data grows.
"Effective data modeling is fundamental in data engineering, serving as the blueprint for building scalable and optimized databases and warehouses." – DataCamp
A strong schema design ensures that storage is used wisely and data retrieval is lightning-fast. It also establishes the rules and relationships that keep data accurate and consistent, even as systems handle larger volumes. Today’s data modeling approach requires balancing speed and maintainability to meet both analytical and operational demands. By mastering these principles, you’re setting the stage for creating reliable and scalable data systems.
Learning Curve
To get started, focus on mastering normalization techniques. For example, use 3NF (Third Normal Form) to reduce redundancy or opt for denormalization when analytics demand faster query speed. Always declare the "grain" of your datasets upfront - for instance, specify whether a table represents "one row per customer per month" or "one row per order line." This clarity avoids mismatched joins and keeps performance consistent.
Familiarize yourself with SQL-based databases like PostgreSQL and MySQL for structured data, and explore NoSQL systems like MongoDB and Cassandra for more flexible models. Modern cloud data warehouses, including Snowflake and BigQuery, come with unique optimization techniques such as partitioning, clustering, and materialized views. Learning these platform-specific features is crucial for building models that perform efficiently.
Practical Applications
When organizing your data, think in layers:
- A raw layer that mirrors source systems.
- A core layer with standardized, cleaned data.
- Serving marts optimized for business intelligence (BI) tools.
For tracking historical changes, implement Slowly Changing Dimensions (SCD Type 2). This technique, which uses start and end timestamps, allows you to create "as-was" reports - essential for understanding past data states.
Tools like dbt help elevate your modeling process by treating data models like software code. You can integrate version control and automated testing directly into your workflow. To maintain data integrity, enforce primary and foreign keys, which can catch errors before they become bigger issues. For cloud platforms, take advantage of features like Snowflake’s search optimization or BigQuery’s clustering to cut down on query costs and improve speed.
Relevant Tools or Platforms
| Tool/Platform | Primary Use Case | Key Features |
|---|---|---|
| dbt (data build tool) | Transformation & Modeling | Modular SQL, version control, automated documentation |
| Snowflake/BigQuery | Cloud Data Warehousing | Automatic scaling, materialized views, clustering |
| dbdiagram.io | Schema Visualization | Code-based DBML, AI-powered design, SQL import/export |
| Apache Iceberg/Delta Lake | Lakehouse Table Formats | ACID transactions, schema evolution, time travel |
| Erwin Data Modeler | Enterprise Design | Relational/multidimensional modeling, source-to-target mapping |
4. ETL/ELT Pipeline Design and Orchestration
Core Importance
Pipeline design serves as the backbone of data engineering, ensuring that data moves seamlessly from its source to destinations where it can inform business decisions. Whether it's customer records, financial transactions, or sensor data, the efficiency and reliability of your pipelines determine how quickly and accurately this information becomes actionable. A key distinction to understand is between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform), as this choice shapes how your data infrastructure scales and adapts over time.
"Data engineers are the lifeblood of any data-driven organization. They accelerate time to value and clear bottlenecks that slow productivity." – Snowflake
In an ETL process, data is transformed on a separate processing server before being loaded into the target system. On the other hand, ELT loads raw data directly into a cloud warehouse, where transformations are performed. The rise of modern cloud platforms like Snowflake and BigQuery, known for their computational power, has made ELT an increasingly popular choice. These platforms handle transformations more efficiently than traditional staging servers. With global data creation projected to hit 149 zettabytes in 2024, selecting the right approach is critical for managing large-scale data processing.
Learning Curve
Understanding when to use ETL versus ELT is essential. Opt for ETL when dealing with sensitive data that requires masking or anonymization, such as Personal Identifying Information (PII), before it reaches storage. ETL is also better suited for systems that cannot handle complex transformations. Choose ELT for large data volumes, especially when using cloud warehouses or when retaining raw data for future analysis is a priority. The flexibility of ELT allows businesses to reprocess raw data as needs evolve, without having to re-extract it from the source.
To build efficient pipelines, focus on mastering key concepts like idempotency, implementing incremental data loads through Change Data Capture (CDC), and using partitioning strategies (e.g., by date or region) to enable parallel processing. These practices improve efficiency and ensure safe retries in case of failures.
Practical Applications
A well-structured pipeline often follows the Medallion Architecture, which organizes data into layers for better management. The Bronze layer captures raw data exactly as it appears in the source systems. The Silver layer refines this data by cleaning and filtering it. Finally, the Gold layer aggregates data into formats tailored for analytics and business insights. This layered approach simplifies troubleshooting and ensures clear checkpoints for data quality.
For staging areas, use columnar file formats like Parquet to speed up read and write operations while minimizing I/O time. Instead of discarding invalid records, consider quarantining bad data for later review. This approach prevents data loss while maintaining the overall flow of the pipeline. Integrate automated testing into each stage of the pipeline with tools like Great Expectations or dbt tests, rather than leaving validation as a final step. Additionally, design pipelines to handle schema drift, so they can adapt to changes in source data formats, such as when a vendor modifies a column or adds new data types. These practices ensure a robust and adaptable pipeline that can handle both current and future challenges.
Relevant Tools or Platforms
| Tool/Platform | Primary Use Case | Key Strengths |
|---|---|---|
| Apache Airflow | Workflow Orchestration | Python-based DAGs, handles complex dependencies, industry standard |
| dbt (data build tool) | SQL Transformations | Enables version control, modular code, and automated testing |
| Fivetran/Airbyte | Data Movement | Offers pre-built connectors and automated schema management |
| Dagster/Prefect | Modern Orchestration | Focuses on asset-centric design, supports local testing, and improves developer experience |
| Snowflake/BigQuery | Cloud Warehouses | Provides native compute for ELT and automatic scaling |
5. Cloud Platform Expertise
Core Importance
Cloud platforms have become a cornerstone for data engineers. The growing reliance on managed and scalable services highlights the need for cloud proficiency, making it a must-have skill in today’s job market. Whether it’s AWS, Google Cloud Platform, or Microsoft Azure, knowing how to work with these platforms is key to building systems that can keep up with an organization's expanding data needs.
"Cloud platform expertise has shifted from advantageous to essential." – Joey Gault, dbt Labs
Managed services simplify the process by taking care of operational tasks like server configurations and backups. Tools such as Amazon RDS, Cloud SQL, and Azure Database for PostgreSQL handle these responsibilities automatically. Additionally, modern cloud warehouses separate compute from storage, allowing you to scale while paying only for what you use. This flexibility helps control costs without sacrificing performance.
Learning Curve
If you’re new to cloud platforms, start by mastering one of the major providers before exploring others. While AWS, Google Cloud, and Azure offer similar core services, their names and interfaces differ. Begin with foundational services like blob storage (e.g., Amazon S3 or Google Cloud Storage), flexible compute options (such as EC2 or Azure VMs), and managed databases. These are the building blocks of almost every data pipeline.
Beyond these basics, delve into Infrastructure as Code (IaC) tools like Terraform or Pulumi. Understanding distributed systems, auto-scaling, and serverless computing models is equally important for designing efficient architectures. Familiarity with Identity and Access Management (IAM) policies and compliance regulations like GDPR is crucial for production systems. These skills form the backbone of creating scalable, secure, and cloud-native solutions.
Practical Applications
Cloud platforms that integrate storage and compute offer significant performance advantages. For instance, Snowflake provides multi-cloud compatibility with its architecture that separates storage from compute. Databricks is a strong choice for Spark-based machine learning and collaborative analytics, while Google BigQuery delivers serverless, scalable query processing without requiring infrastructure management. The best platform for you depends on your priorities - whether it’s ease of use, advanced machine learning capabilities, or serverless simplicity.
Cost optimization is another critical area. Implement tiered storage strategies to manage expenses by moving data between hot, warm, and cold storage based on usage. For example, frequently accessed data can stay in high-performance storage, while older or less critical data shifts to cost-effective cold storage. As AI workloads become more common, consider how your cloud setup supports tools like vector databases and retrieval-augmented generation for AI applications.
Relevant Tools or Platforms
| Cloud Provider | Primary Data Warehouse | Blob Storage | Managed SQL Databases |
|---|---|---|---|
| AWS | Amazon Redshift | Amazon S3 | Amazon RDS |
| Google Cloud | Google BigQuery | Google Cloud Storage | Cloud SQL |
| Microsoft Azure | Azure Synapse | Azure Blob Storage | Azure Database for PostgreSQL |
sbb-itb-61a6e59
6. Data Governance, Quality, and Observability
Core Importance
Once you've mastered SQL, Python, and pipeline design, the next step is ensuring your data is trustworthy and well-managed. This is where data governance steps in. It’s the backbone of maintaining data integrity and compliance, especially in today’s complex cloud environments. Without strong governance, pipelines can falter, analytics can become unreliable, and trust in data can erode. For stakeholders, confidence in data accuracy, security, and alignment with regulations like GDPR, CCPA, and HIPAA is non-negotiable.
"Amidst the data deluge, one thing is paramount: trust. Trust in the pristine quality and unwavering accuracy of our data. That's why crafting a single source of truth and an ironclad data governance strategy stands as our critical mission." – Pavel Ermakov, Sr. Director, Regional Head of Data Excellence, Daiichi Sankyo Europe GmbH
Observability has also become a critical piece of the puzzle. It’s not just about monitoring pipelines anymore - it’s about keeping an eye on data freshness, volumes, schema drift, and anomalies to address problems before they affect downstream users. With over 94% of enterprises relying on cloud technologies for their data operations, mastering governance and observability is no longer optional - it’s essential. These practices ensure that data remains accurate and compliant throughout its lifecycle, building on the foundation of solid pipeline designs.
Learning Curve
To excel in governance, you need to shift your mindset from simply building systems to thinking holistically about how they operate. Start by getting familiar with data contracts - these are agreements that define schemas and quality expectations, preventing upstream changes from breaking downstream processes. Automated quality checks are another must-have, catching errors early and saving time.
Other key practices include setting up idempotent jobs - jobs that can be retried without causing duplicates or inconsistencies - and using version-controlled documentation and lineage tracking to maintain clarity as teams grow. Perhaps most importantly, learning to translate technical constraints into business outcomes will help you communicate effectively with stakeholders. These strategies don’t just stand alone - they integrate seamlessly with your data architecture and reinforce the pipeline and modeling methods you’ve already developed.
Practical Applications
When transforming raw data into actionable insights through ELT processes, governance ensures that every step delivers reliable results. The transformation layer, in particular, has become a focal point for quality checks. Tools like dbt and Dagster can help enforce data quality and track lineage across workflows.
In decentralized setups like Data Mesh architectures, governance takes on a federated approach. Policies are tailored to data sensitivity, and automation plays a big role - think masking, encryption, and access controls to maintain compliance. Additionally, keeping tabs on pipeline latency, data drift, and performance helps you resolve issues before they escalate.
Relevant Tools or Platforms
| Tool Category | Key Platforms | Primary Function |
|---|---|---|
| Data Quality | Great Expectations, Soda, dbt | Automated testing, schema validation, anomaly detection |
| Governance Platforms | Collibra, Alation | Business glossary, policy enforcement, data cataloging |
| Observability | Monte Carlo, Datadog | Monitoring data freshness, schema changes |
| Orchestration | Dagster, Airflow, Prefect | Dependency management, lineage tracking, error recovery |
7. Problem-Solving and Cross-Functional Communication
Core Importance
Technical expertise may be the backbone of engineering, but the ability to solve complex problems and link technical work to business objectives is what sets outstanding engineers apart. Debugging distributed systems and explaining technical concepts in terms that highlight their business value are crucial skills. When systems fail or data veers off course, the ability to resolve issues across interconnected platforms while keeping stakeholders informed is indispensable.
The role of data engineers has transformed significantly. They’re no longer just "pipeline builders" - they’re architects of systems that align technical frameworks with organizational goals. This means working closely with data scientists, analysts, and even marketing teams, ensuring raw data is transformed into insights that drive decisions. With data engineering roles doubling from 2021 to 2022 and offering a median annual salary of $130,000, the demand for engineers who can think systematically and communicate clearly has never been more apparent.
"Data engineers are no longer just builders. They are system thinkers who drive efficiency, agility, and resilience." – Jim Kutz, Airbyte
This shift in expectations underscores the importance of refining soft skills alongside technical expertise.
Learning Curve
Developing the human side of engineering can often be more challenging than mastering new technologies. Building strong business acumen is key - understanding how different departments function ensures that your technical decisions deliver measurable value. Active listening plays a big role here: before jumping into solutions, take the time to fully grasp the business needs and constraints.
Clear documentation and well-structured runbooks are non-negotiable. These tools ensure that distributed teams can maintain and scale complex systems as the organization grows. Treating data as a product - complete with service level agreements (SLAs) and a focus on user experience - helps manage expectations and builds trust. Combining technical expertise with straightforward communication ensures your systems are both efficient and reliable.
Practical Applications
In practice, these skills shape your daily work. For example, when troubleshooting inefficiencies, focus on tasks that have the most significant business impact rather than those that align with personal technical preferences. If you’re making schema changes, explain them in terms that non-technical stakeholders can easily understand. This ability to translate technical details into actionable insights is critical for driving informed decision-making.
Cross-functional collaboration also means engaging in agile development processes and ensuring your work aligns with broader organizational goals. For example, designing idempotent jobs can help systems recover automatically, minimizing disruptions. The challenge lies in striking a balance between technical precision and practical business needs. By doing so, you create infrastructure that not only functions well but also actively supports the company’s objectives. In short, problem-solving paired with strong communication skills completes the toolkit every modern data engineer needs.
Top 5 SKILLS To Become A DATA ENGINEER In 2026 | MUST Know SKILLS For A DATA ENGINEER | Simplilearn
Skills Comparison Table
Take a look at the table below to guide your learning journey and understand the essential aspects of each skill.
| Skill | Core Importance | Learning Difficulty | Practical Uses | Related Tools |
|---|---|---|---|---|
| SQL Mastery | Critical (Foundation) | Moderate | Data retrieval, query optimization, performance tuning, implementing business logic | PostgreSQL, Snowflake, BigQuery, MySQL |
| Python Programming | High (Versatility) | Moderate | Pipeline automation, API integration, custom transformations, data manipulation | Pandas, PySpark, SQLAlchemy |
| Data Modeling | High (Architecture) | High | Designing scalable schemas, creating semantic layers, optimizing query performance | dbt, Power BI, ER/Studio |
| ETL/ELT & Orchestration | Critical (Operations) | High | Moving data between systems, managing job dependencies, designing transformation workflows | Airflow, Airbyte, Dagster, Fivetran |
| Cloud Platform Expertise | Essential (Infrastructure) | Moderate to High | Managing scalable storage/compute, cost optimization, implementing serverless functions | AWS (S3/Redshift), Azure, Google Cloud |
| Data Governance & Quality | High (Trust) | Moderate | Ensuring data accuracy, compliance (e.g., GDPR), automated observability, anomaly detection | Great Expectations, Soda, Unity Catalog |
| Problem-Solving & Communication | High (Strategic) | High | Debugging distributed systems, aligning with stakeholders, translating technical concepts | Slack, Jira, Tableau |
This table outlines the essential components of each skill, offering a clear roadmap for building a solid foundation in data engineering.
Each skill plays a distinct role in modern data practices, yet they all work together to create a comprehensive toolkit. For example, SQL and ETL/ELT are the backbone of daily operations, enabling efficient data movement and transformation. Python adds flexibility, allowing for automation and customized solutions. Data modeling, though challenging, is crucial for creating scalable systems that can handle growth without breaking down.
With the rise of cloud computing, cloud expertise has become indispensable. Managed services might make initial setup straightforward, but achieving cost efficiency and resilience demands a deeper understanding. Similarly, data governance and quality have grown into vital disciplines, ensuring data remains accurate and compliant in an increasingly regulated world.
Soft skills like problem-solving and communication are just as critical. As Manik Hossain aptly put it:
"The most future-proof skill isn't a technology - it's contextual thinking."
These skills are irreplaceable, especially as systems become more complex and require human insight to navigate.
It's worth noting that while some skills, like SQL, might seem easier to pick up, true mastery takes time. Advanced concepts such as window functions or optimizing large-scale queries can take years to perfect. Similarly, cloud platforms might offer user-friendly interfaces, but designing for scalability and efficiency is a skill that requires experience.
Conclusion
Data engineering is a field that demands a mix of technical expertise, strategic foresight, and scalable systems. Core tools like SQL, Python, cloud platforms, and orchestration frameworks are essential for building efficient workflows. Alongside these, strong data modeling practices and governance ensure the reliability and compliance of your infrastructure. But the technical side alone isn’t enough - you also need sharp problem-solving skills and the ability to communicate complex ideas clearly.
The industry is expanding fast, with job opportunities expected to grow by 21% between 2018 and 2028. This reflects how vital data engineers have become in today’s organizations.
If you’re looking to break into this field, practical experience is key. Start by working on real-world projects: build end-to-end pipelines with tools like Airbyte and dbt, contribute to open-source initiatives, or tackle challenges like web scraping. Certifications such as AWS Certified Data Analytics or Google Professional Data Engineer can also help you demonstrate your cloud expertise.
The landscape of data engineering is constantly shifting - from the rise of ELT architectures to the integration of AI-driven tools. Staying ahead means committing to lifelong learning and engaging with the broader data engineering community. By building on the technical skills covered in this article and embracing new challenges, you can carve out a resilient and rewarding career in this ever-evolving field.
FAQs
What’s the difference between ETL and ELT in data engineering?
ETL (Extract, Transform, Load) involves processing data by transforming it first and then loading it into the target system. This method has been a go-to for smaller datasets or when dealing with legacy systems.
ELT (Extract, Load, Transform), however, flips the process. Raw data is loaded directly into a data lake or warehouse, and the heavy lifting of transformation is done using the warehouse's computing power. This approach is better suited for managing large, complex datasets, especially when leveraging modern cloud-based platforms.
The main distinction comes down to when and where the data transformation occurs: ETL processes data before loading it, while ELT processes data after it’s been loaded.
How can data engineers optimize cloud costs without sacrificing performance?
To keep cloud costs in check while maintaining performance, start by tailoring your architecture to match your workload needs. Analyze your data pipelines to gauge factors like latency, data volume, and query complexity. Then, select the cloud services that best fit those requirements. For instance, serverless compute works well for tasks with fluctuating demand, while provisioned clusters are better suited for consistent workloads. Take advantage of cost-saving tools such as auto-scaling, spot instances, and storage tiering. For example, store frequently accessed data on faster, more expensive storage, and move less-used data to lower-cost archival options.
Keeping an eye on usage is essential for effective cost management. Use monitoring tools to track metrics like CPU, memory, and I/O utilization, and scale back any over-provisioned resources. Fine-tuning queries - like partitioning data or reducing the amount scanned - can also help cut compute costs significantly. Lastly, adopt a cost-conscious approach by embedding cost considerations into your development workflow. This could include running automated tests to assess cost impact and collaborating with stakeholders to strike the right balance between performance and budget. With this strategy, you can build efficient, reliable data pipelines without breaking the bank.
Why are problem-solving and communication important skills for data engineers?
Problem-solving is a crucial skill for data engineers. They’re responsible for designing and maintaining intricate systems that transform raw data into formats that businesses can actually use. This means they need to act fast when issues arise - whether it’s a data quality hiccup or a pipeline failure - to keep everything running smoothly. On top of that, they have to take vague business requirements and turn them into clear, actionable technical solutions. This is how scalable and efficient data infrastructure gets built.
Equally important is communication. Data engineers often find themselves working alongside stakeholders from different areas - business, analytics, and IT teams. They need to bridge the gap by translating business needs into technical terms, explaining technical constraints to non-technical colleagues, and working hand-in-hand with teams like data scientists and analysts. Clear communication not only prevents misunderstandings but also keeps projects on track and fosters a stronger data-driven culture across the organization.