
How to Transition into Data Engineering in 2026
Data engineering in 2026 is one of the most sought-after career paths in tech, offering high salaries and strong job demand. If you're looking to break into this field, here’s what you need to know:
- What Data Engineers Do: They design, build, and maintain systems for data movement, storage, and processing. Responsibilities include creating data pipelines, managing data warehouses, and ensuring data quality and reliability.
- Why It’s a Top Career: Median salaries are $131,000, with senior roles earning up to $220,000. Demand is expected to double between 2025 and 2030.
- Who Can Transition: Software engineers, data analysts, machine learning engineers, and DevOps professionals can leverage their existing skills while learning data-specific tools.
- Key Skills to Learn: Python, SQL, data modeling, cloud platforms (AWS, GCP, Azure), orchestration tools (Apache Airflow), and frameworks like dbt.
- Learning Roadmap: Focus on Python and SQL first, then move to databases, cloud platforms, and advanced tools like Spark and Kafka. Build end-to-end projects to showcase your abilities.
Transitioning into data engineering typically takes 6–12 months of focused effort. Structured programs, such as top data engineering boot camps or mentorship, or comparing data engineering bootcamps, can accelerate your learning and help you land a role in this high-demand field.
Understanding the Data Engineer Role in 2026
Key Responsibilities of a Data Engineer
By 2026, data engineers are at the forefront of designing, building, and maintaining systems that handle the movement, storage, and processing of data. Their primary tasks include creating batch and streaming pipelines, using star and snowflake schemas for data modeling, and managing cloud-based data warehouses or lakehouses. The focus has shifted significantly toward architectural design, moving away from manual ETL scripting.
A major part of the role now involves data reliability engineering. This includes implementing data contracts, using observability tools, and tracking data lineage to ensure systems remain reliable and downtime is minimized. Additionally, data engineers are responsible for developing pipelines that support the entire machine learning lifecycle. This includes working with feature stores and vector databases like Pinecone and Milvus, which enable real-time AI processing. Another emerging responsibility is managing cloud costs through FinOps, where engineers monitor and optimize expenses on platforms like Snowflake and BigQuery - marking a shift from earlier times when compute costs were less of a priority.
As Interview Sidekick aptly puts it:
"AI automates labor; data engineers automate decisions".
These expanded responsibilities require a deep understanding of an advanced tech stack, which we’ll explore next.
The 2026 Data Engineering Tech Stack
The evolving role of data engineers is powered by a sophisticated tech stack. At its core, Python and SQL remain indispensable for data manipulation, automation, and querying. For orchestration, Apache Airflow continues to lead in managing Directed Acyclic Graphs (DAGs), often paired with Cosmos to streamline dbt workflows. dbt (Data Build Tool) has become the go-to framework for modular SQL transformations, offering version control and testing directly within the warehouse.
The widely adopted "Lakehouse" architecture combines the strengths of data lakes and warehouses, with platforms like Snowflake, Databricks, and Google BigQuery leading the charge. Table formats such as Apache Iceberg, Delta Lake, and Apache Hudi enhance these systems by providing ACID transactions and time-travel features on top of object storage solutions like AWS S3. A growing trend is AI-assisted coding, or "vibe coding", where tools like GitHub Copilot and AWS Q generate boilerplate code and documentation, enabling engineers to focus more on architectural decisions.
Proficiency in at least one major cloud provider - AWS, GCP, or Azure - is now essential, along with expertise in their specific data services like AWS Glue, S3, and Redshift. The tech stack also increasingly incorporates vector databases such as Pinecone, Milvus, and Chroma to support Generative AI and Retrieval-Augmented Generation (RAG) workflows.
Data Engineering Jobs in the US Market
Data engineering salaries in 2026 vary based on experience and location, with tech hubs offering the most competitive pay. San Francisco leads the pack, with salaries ranging from $148,000 to $186,000, followed by New York at $130,000 to $160,000, and Seattle at $125,000 to $155,000. Remote roles, which have become more common, typically offer between $100,000 and $145,000. The flexibility of remote or hybrid work arrangements has significantly improved work-life balance for many professionals.
According to the World Economic Forum’s 2025 Future of Jobs Report, the demand for big data specialists is expected to grow by over 100% between 2025 and 2030. These insights underline the importance of aligning your current skills with the evolving demands of the field in 2026.
How I would learn Data Engineering in 2025 (if I could start over) – Built by a Data Engineer
Mapping Your Background to Data Engineering Skills
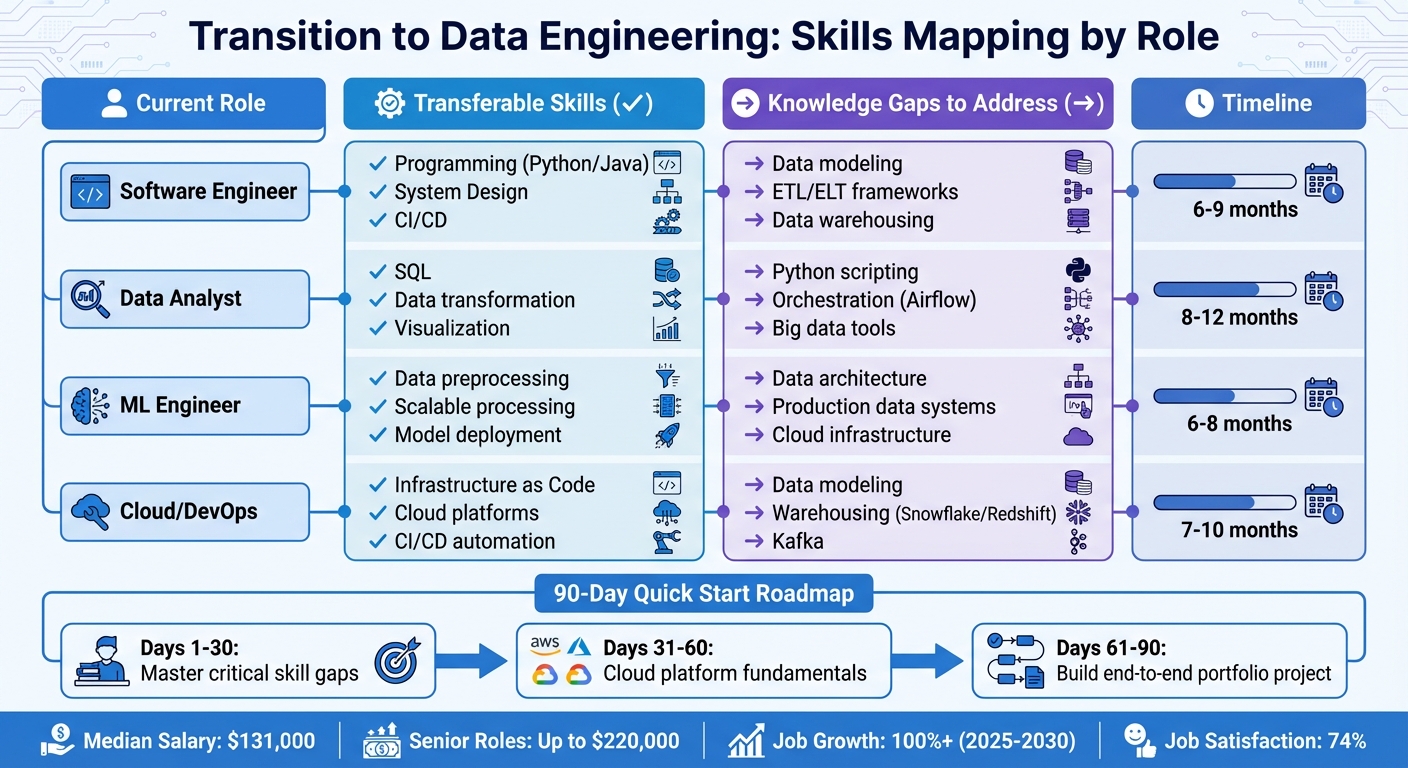
Data Engineering Career Transition Guide: Skills Mapping by Role 2026
Core Skills for Data Engineers in 2026
If you're eyeing a career in data engineering, there are a few skills you just can't skip. Python and SQL are at the top of the list. Python is your go-to for scripting, automation, and data wrangling, while SQL is essential for querying and transforming datasets. But that's just the starting point.
You'll also need to get comfortable with orchestration tools like Apache Airflow or Dagster, which are crucial for managing workflows. Plus, knowing how to use dbt for modular SQL transformations is a game-changer. On the storage side, familiarity with cloud warehouses like Snowflake, BigQuery, and Redshift is key. And don’t overlook lakehouse formats like Apache Iceberg and Delta Lake, which bring ACID transactions to object storage.
Another area gaining traction is data reliability engineering. This includes maintaining reliable data contracts, tracking data lineage with tools like OpenLineage, and using observability platforms such as Great Expectations or Monte Carlo to ensure data quality. As cloud costs rise, FinOps awareness is becoming increasingly important. You'll need to monitor expenses and optimize partition strategies to keep those cloud bills in check.
Generative AI is also reshaping the field. Tools like Chroma, Pinecone, and Milvus are becoming essential for working with vector databases, which support AI applications. This shift has given rise to "vibe coding", where engineers use tools like GitHub Copilot to handle repetitive coding tasks, freeing them up to focus on system design and architecture.
Transitioning from Common Roles
Your current role might already provide a strong foundation for data engineering, but it’s important to identify where you excel and what skills you need to develop.
- Software Engineers: Your programming expertise in Python, Java, or Scala, along with system design and CI/CD pipeline experience, gives you a solid start. To transition, focus on data modeling (think star and snowflake schemas), learning ETL/ELT frameworks like Apache Spark, and mastering data warehousing concepts.
- Data Analysts: Your deep SQL knowledge, experience with data transformation, and understanding of business logic are valuable. To move into data engineering, work on Python scripting, learn orchestration tools like Airflow, and get hands-on with cloud infrastructure and distributed systems.
- Machine Learning Engineers: You’re already skilled in data preprocessing, managing large datasets, and deploying models. To stand out as a data engineer, focus on data architecture, optimizing data warehouses, and ensuring pipeline reliability.
- Cloud and DevOps Engineers: Your background in Infrastructure as Code (using tools like Terraform), CI/CD automation, and cloud service management is a great asset. To pivot into data engineering, learn data modeling, get familiar with data warehousing platforms like Snowflake or Redshift, explore streaming tools like Kafka, and understand the business side of analytics workflows.
Using a Skills Mapping Table
A skills mapping table can help you clearly see where you’re strong and where you need to grow. Here’s an example to guide you:
| Current Role | Transferable Skills | Key Knowledge Gaps to Address |
|---|---|---|
| Software Engineer | Programming (Python/Java), System Design, CI/CD | Data modeling, ETL/ELT frameworks, Data warehousing |
| Data Analyst | SQL, Data transformation, Visualization | Python scripting, Orchestration (Airflow), Big data tools |
| ML Engineer | Data preprocessing, Scalable processing | Data architecture, Production data systems, Cloud infrastructure |
| Cloud/DevOps | Infrastructure as Code, Cloud platforms | Data modeling, Warehousing (Snowflake/Redshift), Kafka |
This table can guide your learning journey. Start with a 90-day roadmap:
- Spend the first 30 days tackling your most critical skill gaps.
- Dedicate the next 30 days to mastering cloud platform fundamentals.
- Use the final 30 days to build an end-to-end portfolio project that demonstrates your new skills.
sbb-itb-61a6e59
Building Your Learning Roadmap for Data Engineering
If you're aiming to become a data engineer, creating a structured learning plan over 6–12 months can help you build the skills needed to land a job in this field. Breaking this journey into focused phases will make the process more manageable and effective.
Start with the basics and gradually work your way up to advanced concepts and practical applications.
Phase 1: Master Python and SQL
Begin by mastering Python, focusing on essential programming concepts like functions, loops, and processing files or JSON data. Make sure you can write modular, clean code and incorporate testing frameworks like pytest to ensure your code is reliable.
On the SQL side, dive deeper than basic queries. Learn advanced techniques, such as window functions like ROW_NUMBER and LAG/LEAD, and practice using Common Table Expressions (CTEs). Understanding query execution plans is also crucial for optimizing performance.
Don’t skip over the fundamentals of Linux, Git, and core data structures either. These skills form the backbone of any data engineering workflow. As Jim Kutz, a data analytics expert, emphasizes:
"The world needs more engineers who can transform complexity into clarity through well-structured, validated, scalable data pipelines."
Phase 2: Learn Databases, Warehousing, and Modeling
This phase focuses on understanding how data is stored and organized. Study both relational databases (like PostgreSQL) and NoSQL options (like MongoDB). Then, shift your attention to cloud-native data warehouses such as Snowflake, BigQuery, or Redshift.
Dimensional modeling is another key skill to develop. Learn how to design star and snowflake schemas, manage Slowly Changing Dimensions (SCDs), and use surrogate keys effectively. Explore lakehouse architectures using tools like Apache Iceberg, Delta Lake, or Apache Hudi, which enable ACID transactions on object storage.
Phase 3: Explore Big Data, Cloud, and Orchestration
Once you’ve mastered storage and modeling, it’s time to scale up. Learn distributed data processing with Apache Spark, focusing on Spark SQL and DataFrames. Pick a major cloud provider - AWS, GCP, or Azure - and delve into its core data services. For example, AWS users might focus on S3 and Glue, while GCP users could explore Dataflow.
Pipeline orchestration is another critical area. Tools like Apache Airflow, Prefect, or Dagster help you manage complex workflows. While Airflow is widely used, Dagster is gaining attention for its metadata-driven, asset-centric approach. Additionally, explore real-time data processing frameworks like Kafka, Flink, or AWS Kinesis. To round out this phase, learn FinOps practices to optimize cloud costs.
Phase 4: Build End-to-End Projects and Portfolios
Finally, apply what you’ve learned by building complete, production-grade pipelines. These should cover data ingestion (e.g., from APIs or Change Data Capture), transformation (using tools like dbt), and cloud storage. Make sure your projects include key practices like idempotency, retry logic, and CI/CD pipelines with tools like GitHub Actions. Use Terraform to automate infrastructure deployment.
To ensure reliability, incorporate observability tools like Great Expectations for data quality testing and OpenLineage for tracking lineage. Your portfolio should showcase your ability to create pipelines that are not only functional but also reliable, cost-efficient, and maintainable. As Rishabh Jain from Interview Sidekick puts it:
"AI automates labor; data engineers automate decisions."
This phased approach equips you with the skills and experience to confidently step into a professional data engineering role.
| Phase | Focus Area | Key Technologies |
|---|---|---|
| 1 | Fundamentals | Python, SQL, Git, Linux, Data Structures |
| 2 | Storage & Modeling | PostgreSQL, Snowflake, MongoDB, Star/Snowflake Schemas |
| 3 | Scaling & Ops | Spark, Airflow, AWS/GCP/Azure, Kafka |
| 4 | Professionalism | Terraform, GitHub Actions, Great Expectations, dbt |
Using Structured Programs and Mentorship
The Value of Structured Training
Once you’ve mapped out your phased learning plan, structured programs and mentorship can be game-changers in turning raw skills into professional-level expertise and passing your analytics engineering interviews. Let’s face it - trying to self-teach with so many technologies out there, like Spark, Flink, Airflow, Iceberg, and various AI-driven platforms, can feel like drinking from a firehose. Structured programs simplify this chaos by offering a clear, goal-oriented path that takes you from the basics to being job-ready.
What sets the best programs apart is their focus on architectural thinking and trade-off analysis instead of just memorizing syntax. This approach is especially relevant as AI tools increasingly handle repetitive coding tasks, freeing engineers to focus on creative problem-solving and designing resilient systems. These programs don’t just teach you the fundamentals - they immerse you in hands-on, real-world projects that sharpen your ability to design and make critical decisions.
How DataExpert.io Academy Can Help
DataExpert.io Academy provides an immersive learning experience with access to premium platforms like Databricks, AWS, Snowflake, and Astronomer. Their curriculum is built around the full 2026 tech stack, including tools like Apache Iceberg, dbt, Spark, Airflow, and cutting-edge AI platforms like LLMs and RAG.
The programs feature over 20 homework assignments and a capstone project designed to replicate real-world business scenarios. A standout offering is the 15-week Data and AI Engineering Challenge, which includes insights from 15 industry-leading guest speakers. With a stellar 4.9/5 rating on Trustpilot based on 637 reviews, many students rave about the program’s practical focus. Some graduates even report doubling their salaries after completing the training.
Comparing DataExpert.io Academy Plans
Structured training combined with expert mentorship can accelerate your journey from theory to production-ready skills. Below is a breakdown of the available plans, each designed to help you advance efficiently.
| Plan | Price (USD) | Duration | Prerequisites | Key Outcome |
|---|---|---|---|---|
| 15-week Data & AI Challenge | $7,497 | 15 Weeks | Intermediate Python & SQL | Full-stack readiness for Data, Analytics, and AI Engineering roles |
| Winter 2026 Analytics Engineering Camp | $3,000 | 5 Weeks | Basic SQL skills | Snowflake, dbt, and Airflow mastery for analysts |
| Winter 2026 Data Engineering Boot Camp | $3,000 | 5 Weeks | Intermediate Python & Spark exposure | Databricks on AWS and Spark proficiency |
| Spring 2026 AI Engineering Boot Camp | $3,000 | 5 Weeks | Python & AI basics | Expertise in RAG, AI Agents, and MLOps |
| All-Access Subscription | $125/mo or $1,500/yr | Self-paced | Python & SQL proficiency | Access to 250+ hours of content, platforms, and community |
| Content Pass | $100/mo or $800/yr | Self-paced | None | Access to all content (bring your own cloud) |
The boot camps come with lifetime access to course content, guest speaker sessions, capstone projects, and one-on-one mentor support. For those who prefer a more flexible approach, self-paced subscriptions allow you to learn at your own speed while staying connected to a vibrant community of learners and professionals.
Conclusion
Key Takeaways
As we look ahead to 2026, data engineering is all about mastering Python, SQL, and making well-informed architectural decisions. It’s no longer just about knowing the syntax - it’s about understanding the trade-offs. For example, when should you use batch processing versus streaming? Why might Apache Iceberg be a better fit than Delta Lake in certain scenarios? These are the kinds of questions that set top engineers apart. Modern interviews have also evolved, moving away from solving LeetCode puzzles to focusing more on scenario-based system design.
The role of data engineers is transforming quickly. Tools like GitHub Copilot are automating routine tasks, freeing up engineers to concentrate on higher-level responsibilities like system design. Ben Lorica, Editor at Gradient Flow, sums it up well:
"The manual tasks that once served as the training ground for junior data engineers are being automated away. The job shifts from plumbing and pipeline babysitting toward architecture, policy-setting, and orchestrating fleets of specialized agents."
This evolution means that skills like designing lakehouse architectures, understanding data contracts, and being aware of FinOps are no longer optional - they’re essential. You'll need to ensure minimal downtime using observability tools, implement practical data security measures, optimize cloud spending, and build systems that are both scalable and resilient.
The financial rewards reflect the growing complexity of the role. Entry-level data engineers in the U.S. can earn between $80,000 and $110,000, while senior roles command salaries of $180,000 to $220,000. According to the World Economic Forum’s Future of Jobs Report, big data specialists are among the fastest-growing roles, with over 100% predicted growth between 2025 and 2030. With 74% of data engineers reporting high job satisfaction, this career path offers not just financial benefits but also a strong sense of professional fulfillment.
Next Steps for Your Transition
If you’re ready to dive into the world of data engineering, consider starting with a 90-day roadmap. Here’s a simple plan:
- First 30 Days: Strengthen your Python and SQL fundamentals.
- Next 30 Days: Focus on learning cloud platforms and data modeling.
- Final 30 Days: Build a production-ready project, like a real-time analytics pipeline or a lakehouse architecture.
For those looking to fast-track their learning, structured programs can help. Instead of spending 6–12 months on self-study, you could join programs like those offered by DataExpert.io Academy. They provide several options:
- The 15-week Data and AI Engineering Challenge ($7,497) for full-stack preparation.
- Focused 5-week boot camps ($3,000 each) to develop specific skills.
- An All-Access Subscription ($125/month or $1,500/year) with 250+ hours of self-paced content and access to tools like Databricks, Snowflake, and AWS.
Chris Garzon, CEO of Data Engineer Academy, highlights the future direction of the field:
"The future of data engineering lies in the ability to integrate technical expertise with business acumen."
With the right plan and resources, transitioning into this high-demand field is entirely achievable.
FAQs
What key skills do I need to successfully transition into data engineering?
To step into the world of data engineering, start by building a solid foundation in Python for scripting and automation, paired with SQL for querying and managing data. A good grasp of core computer science principles - like data structures, algorithms, and system design - is key to creating scalable and efficient data pipelines.
You'll also need to get comfortable with big data frameworks like Apache Spark and Kafka, as well as cloud platforms such as AWS, Azure, or GCP. These are critical for managing today's complex data workloads. On top of that, learning tools like Airflow, dbt, Snowflake, and Databricks will help you design and maintain seamless, end-to-end data pipelines.
To stand out in this competitive field, dive into areas like data governance, observability, and CI/CD practices, which ensure high data quality and smooth operations. If you can also demonstrate knowledge of AI/ML integration and showcase projects with measurable business outcomes, you'll significantly boost your career prospects.
How long does it take to switch to a career in data engineering?
On average, making the leap into a data engineering role takes about 6 to 9 months of dedicated learning, followed by another 2 to 3 months spent job hunting. Of course, this timeline isn’t set in stone - it depends on factors like your prior experience, commitment, and the resources you rely on.
To make the process smoother, focus on developing essential skills such as Python and SQL, along with gaining hands-on experience with tools like Databricks, Snowflake, and Airflow. Enrolling in certifications or structured online courses can also give you a solid starting point and make you more appealing to potential employers. The key to success? Consistency and intentional practice.
How are data engineering roles in 2026 different from previous years?
Data engineering in 2026 has transformed into a more AI-driven, cloud-focused field than ever before. While foundational skills like SQL and Python remain crucial, modern engineers are now expected to be proficient with cloud platforms such as AWS, Azure, and GCP, as well as version control systems and CI/CD pipelines. The emergence of technologies like lakehouse architectures (e.g., Delta Lake) and metadata management tools has shifted priorities from simply managing data warehouses to crafting hybrid systems that combine flexibility and performance.
The job has also become more specialized, with skill requirements varying by experience. Entry-level engineers typically concentrate on mastering SQL, Python, and one cloud platform. In contrast, senior roles demand deeper expertise in tools like Airflow, dbt, Kafka, PySpark, and container orchestration technologies like Docker and Kubernetes. Meanwhile, AI-driven tools have taken over repetitive tasks such as pipeline monitoring, enabling engineers to focus on designing scalable systems and creating data products optimized for AI.
In essence, the role has expanded beyond merely transferring data between systems. Today’s engineers are responsible for building comprehensive data solutions that power real-time analytics, support AI applications, and uphold strong governance standards.