
Horizontal vs. Vertical Scalability in Analytics
Scalability in analytics ensures systems can handle growing data and complex queries efficiently. The two main approaches are horizontal scaling (adding more machines) and vertical scaling (upgrading a single machine). Each method has distinct strengths and limitations, depending on your system's needs.
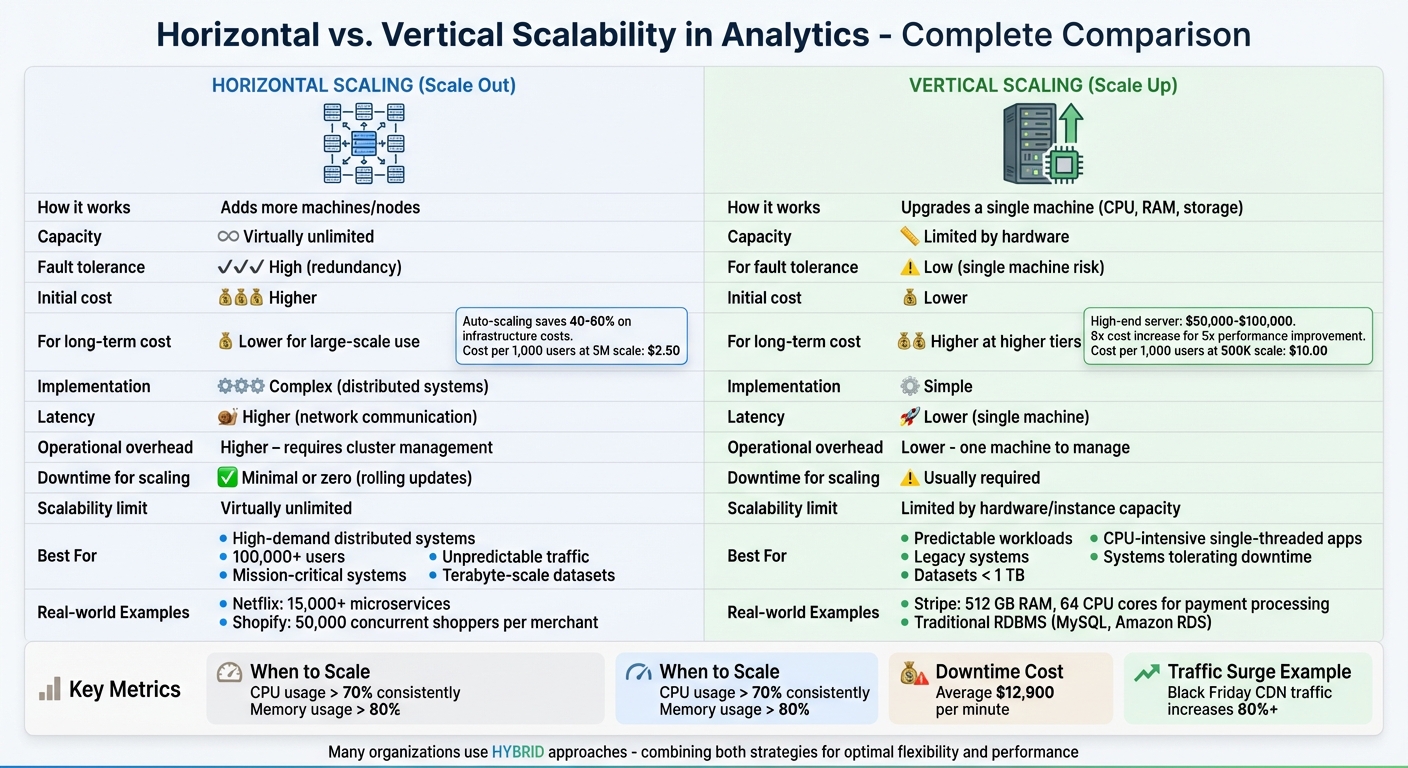
- Horizontal scaling: Adds machines to distribute workloads. This approach offers more capacity, fault tolerance, and elasticity but requires managing distributed systems and networks.
- Vertical scaling: Upgrades a single machine's hardware. It’s simpler to implement and reduces latency but is limited by hardware capacity and creates a single point of failure.
Quick Comparison
| Feature | Horizontal Scaling | Vertical Scaling |
|---|---|---|
| How it works | Adds more machines/nodes | Upgrades a single machine |
| Capacity | Virtually unlimited | Limited by hardware |
| Fault tolerance | High (redundancy) | Low (single machine risk) |
| Cost (initial) | Higher | Lower |
| Cost (long-term) | Lower for large-scale use | Higher at higher tiers |
| Implementation | Complex (distributed systems) | Simple |
| Latency | Higher (network communication) | Lower (single machine) |
Horizontal scaling is ideal for high-demand, distributed systems, while vertical scaling suits smaller, predictable workloads. Many organizations combine both strategies for flexibility and performance. Aspiring data engineers can master data engineering and AI to better navigate these architectural decisions.
Horizontal vs Vertical Scalability: Complete Feature Comparison
Horizontal Scalability in Analytics
What is Horizontal Scalability?
Horizontal scalability, often called "scaling out", involves increasing system capacity by adding more machines to a resource pool instead of upgrading the hardware of a single server. Essentially, rather than making one server bigger or faster, you distribute the workload across multiple machines. These machines work together as a cluster.
Key techniques include load balancers to evenly distribute incoming requests, sharding to divide large datasets into smaller partitions, replication to ensure data availability, and orchestration tools like Kubernetes to manage instances dynamically. This approach helps analytics systems handle growing data volumes and complex queries without sacrificing performance.
However, one of the biggest challenges lies in maintaining data consistency across these distributed nodes. Ensuring ACID compliance and strong consistency often requires advanced protocols like Raft or two-phase commit. That said, for analytics tasks that can tolerate eventual consistency, horizontal scaling provides a powerful solution.
These foundational elements enable the capacity and resilience benefits discussed below.
Benefits of Horizontal Scalability
Horizontal scaling offers several practical and measurable advantages.
One standout benefit is its virtually unlimited capacity. Unlike vertical scaling, which is limited by the largest available hardware, horizontal scaling allows you to keep adding commodity servers as needed.
"Horizontal scaling is 'infinitely scalable' as you can always add another machine while you may not be able to buy a larger machine if you are already using the largest machine available." – MongoDB
Another advantage is fault tolerance. By distributing workloads across multiple nodes, you eliminate single points of failure. If one server goes down, others can continue processing analytics queries, ensuring uninterrupted service. This resilience is critical, especially when downtime can lead to significant financial losses.
Elasticity is another key strength. Systems can automatically scale up during demand spikes (like end-of-month reporting) and scale down during quieter periods, optimizing costs. In fact, auto-scaling can cut infrastructure costs by 40–60% compared to static provisioning for applications with fluctuating traffic. This means you only pay for the resources you actually use.
Horizontal scaling also simplifies geographic distribution. By deploying nodes in different regions, you can store and process data closer to end-users, reducing latency and meeting regional data residency requirements. Modern distributed databases even handle auto-sharding automatically, removing the manual effort from your data engineering team.
Use Cases for Horizontal Scalability
The advantages of horizontal scaling make it indispensable for a variety of high-demand scenarios.
One key application is distributed data processing. Frameworks like Hadoop excel in this area, using parallel processing across multiple nodes. The MapReduce model, for example, breaks down massive analytical queries into smaller tasks that can be executed simultaneously. A well-known example is Google Search, which processes queries across thousands of servers at an enormous scale.
High-concurrency environments also benefit significantly. Real-time gaming, trading platforms, and global SaaS applications rely on horizontal scaling to handle large numbers of simultaneous users. Netflix, for instance, operates over 15,000 microservices in a horizontally scaled system to manage its global streaming and analytics workloads.
For mission-critical systems requiring near-zero downtime, horizontal scaling ensures continuous operations even when individual nodes fail. It also enables compliance with regional data residency regulations by distributing nodes across multiple locations. This makes it a go-to solution for businesses that demand reliability and global reach. Aspiring engineers can compare data engineering bootcamps to find the right training for building these scalable systems.
sbb-itb-61a6e59
Vertical Scalability in Analytics
What is Vertical Scalability?
Vertical scaling, often called scaling up, involves enhancing a single machine's performance by upgrading its hardware components like the CPU, RAM, or storage. Instead of adding more servers to your setup, you focus on improving the existing machine - think of swapping out traditional hard drives for high-speed NVMe SSDs or resizing a virtual machine in cloud environments to a larger instance type. This approach keeps all data processing within one node, eliminating the need for coordinating multiple servers or dealing with network latency.
This streamlined setup brings several notable advantages.
Benefits of Vertical Scalability
While horizontal scaling is great for distributed and fault-tolerant systems, vertical scaling offers a straightforward and low-latency solution for legacy and resource-demanding workloads.
One of its biggest strengths is simplicity. Vertical scaling doesn’t require rewriting code or implementing complex synchronization protocols, which makes it especially appealing for teams working with older systems. Plus, single-node processing simplifies compliance with ACID properties.
Another benefit is reduced latency. Since all operations happen within a single machine, inter-process communication is much faster than network calls between servers. This makes vertical scaling ideal for tasks like complex joins and CPU-heavy analytics.
"Vertical scaling works well for CPU-intensive, single-threaded applications. Database servers running complex queries, machine learning model training, and real-time analytics often perform better on powerful individual machines." – DataCamp
For organizations with predictable growth, vertical scaling can also be cost-efficient. A high-performance server with 128 cores and 1 TB of RAM might cost between $50,000 and $100,000, and licensing fees are often lower compared to running multiple smaller servers, as many software vendors charge per core or server.
However, there’s a trade-off. Vertical scaling creates a single point of failure: if the one powerful server goes down, the entire system goes offline. This can be costly, with downtime averaging $12,900 per minute. Additionally, every server has a hardware limit - eventually, upgrades either become impossible or prohibitively expensive.
Use Cases for Vertical Scalability
The strengths of vertical scaling make it well-suited for certain scenarios.
For instance, single-node OLAP systems benefit significantly from vertical scaling. Real-time analytics involving complex joins run faster because all data resides on one machine, avoiding network delays. Similarly, traditional relational databases like MySQL or Amazon RDS handling small-to-medium workloads often perform better when scaled vertically rather than distributed.
Internal analytics databases that can tolerate occasional downtime for hardware upgrades are another good fit. If your organization doesn’t require constant availability and can manage brief maintenance windows, vertical scaling offers a simpler and more economical solution.
"Vertical scaling is best for less important systems and workloads that aren't likely to need additional scale in the future." – CockroachDB
Lastly, vertical scaling is often the only option for legacy monolithic applications. These systems, which cannot be easily refactored for distributed environments, rely on vertical scaling to meet performance demands. Legacy business intelligence tools are a prime example, as they often lack the flexibility to adapt to distributed architectures.
Comparing Horizontal and Vertical Scalability
Horizontal vs. Vertical Scalability: Comparison Table
When deciding between horizontal and vertical scalability, it’s important to weigh how each option aligns with your infrastructure needs. Here’s a breakdown of their differences across key aspects:
| Feature | Horizontal Scaling (Scale Out) | Vertical Scaling (Scale Up) |
|---|---|---|
| Resource Allocation | Involves adding more machines or nodes | Upgrades the CPU, RAM, or storage of a single machine |
| Cost (Initial) | Higher due to load balancers and multiple instances | Lower since it typically requires a simple hardware upgrade |
| Cost (Long-term) | More economical for large-scale systems | Becomes exponentially expensive at higher tiers |
| Fault Tolerance | High, thanks to redundancy and no single point of failure | Low, as it depends on a single machine |
| Latency | Higher due to network communication between nodes | Lower because processes run on one machine |
| Implementation | More complex, requiring distributed logic and sharding | Simpler, as applications often remain unchanged |
| Operational Overhead | Higher, involving cluster management and synchronization | Lower, with only one machine to manage |
| Downtime for Scaling | Minimal or zero with rolling updates | Downtime is usually required for upgrades |
| Scalability Limit | Virtually unlimited | Limited by hardware or instance capacity |
This table highlights how each approach fits different scalability needs. Vertical scaling might seem more affordable at first, but high-end upgrades quickly become costly. On the other hand, horizontal auto-scaling can cut cloud expenses by 40–60% for applications with fluctuating workloads.
Choosing Between Horizontal and Vertical Scalability
The right choice depends on your business's unique requirements and technical constraints. Vertical scaling works well for monolithic systems that prioritize low latency, while horizontal scaling is better for systems demanding high availability and elastic capacity. Licensing costs are another factor to consider - running a single 32-core server often costs less than managing eight 4-core servers.
For instance, during peak events like Black Friday, content delivery traffic can surge by over 80%. In such cases, horizontal scaling’s flexibility becomes indispensable.
"The choice you make will shape your system's architecture, performance, and costs for years to come." – Daniel Bartholomew, Webscale
Stateless applications, such as web servers and APIs, are ideal for horizontal scaling due to their simplicity. In contrast, stateful services like databases often require advanced strategies like sharding to scale horizontally or may initially rely on vertical scaling for consistency.
"Vertical scaling is best for less important systems and workloads that aren't likely to need additional scale in the future." – CockroachDB
Many companies adopt hybrid strategies to balance their needs. For example, Stripe vertically scales its core payment databases, using powerful machines with 512 GB of RAM and 64 CPU cores to handle millions of transactions daily without data conflicts. Meanwhile, Shopify scales horizontally during flash sales, accommodating up to 50,000 concurrent shoppers per merchant, while vertically scaling its database systems to manage complex inventory queries.
Hybrid and Diagonal Scaling Approaches
What is Hybrid and Diagonal Scaling?
Hybrid and diagonal scaling methods build on the strengths of vertical and horizontal scaling, offering a balanced approach to handling system growth.
Diagonal scaling starts with enhancing a single server's capabilities - upgrading its CPU, RAM, or storage - until it reaches its performance limits. Once optimized, the system is replicated across multiple nodes. This approach combines the efficiency of vertical scaling with the broader capacity of horizontal scaling, ensuring each node operates at its peak before expanding outward.
Hybrid scaling, on the other hand, applies different scaling strategies to different parts of a system. For instance, a database layer might be scaled vertically to maintain data consistency, while the application layer is scaled horizontally to handle fluctuating traffic. This method delays the need for the complexities of fully distributed systems until absolutely necessary.
One of the major advantages of these approaches is their resilience. By distributing workloads across multiple high-performing nodes, they reduce reliance on any single point of failure while minimizing communication delays between processes.
These strategies are frequently used in leading analytics platforms to balance performance, scalability, and reliability.
Examples of Hybrid Scaling in Analytics
The success of hybrid scaling is evident in real-world applications, especially in analytics-heavy environments.
Take Airbnb and Uber as examples. Both companies started with monolithic architectures that they scaled vertically before moving to distributed systems. Airbnb initially ran a monolithic Ruby on Rails application, scaling up by upgrading to larger AWS EC2 instances. As its global user base grew, the company shifted to a service-oriented architecture, horizontally scaling key services like search and booking across regions while continuing to use high-performance instances for compute-heavy tasks. Similarly, Uber began with powerful EC2 instances to support its monolithic application. As the company expanded globally, it distributed services like trip matching and pricing across multiple nodes and regions, while still relying on large instances for real-time location tracking.
In analytics, a common hybrid approach involves scaling a database server vertically to ensure data consistency and low latency for complex queries. Meanwhile, stateless application layers or inference systems are horizontally scaled to handle high traffic volumes. For example, Kubernetes environments often use Vertical Pod Autoscalers (VPA) to adjust container resources and Horizontal Pod Autoscalers (HPA) to manage the number of replicas, creating a smooth hybrid solution.
For new analytics projects, starting with vertical scaling simplifies deployment and helps maintain data integrity. As traffic increases and system demands evolve, transitioning to a hybrid or horizontal scaling model can provide the flexibility and capacity needed. Observability tools can guide this transition, signaling when it’s time to expand beyond vertical scaling.
Implementation Considerations for Analytics Scalability
Factors to Evaluate
Choosing the right approach to scaling analytics systems requires careful consideration of several key factors, especially when it comes to architecture and cost management over time.
Data consistency requirements play a crucial role. If you're working with systems that demand strict ACID compliance - like those used in payment processing or financial reporting - vertical scaling is often the better choice. Keeping all data on a single node ensures consistency and avoids the complexities of distributed systems. A good example is Stripe, which uses high-performance PostgreSQL databases on single machines equipped with 512 GB of RAM and 64 CPU cores. This setup allows Stripe to handle millions of transactions daily without the risks associated with distributed data conflicts. On the other hand, horizontal scaling can introduce challenges, such as eventual consistency or the need for distributed transaction management, which may not be suitable for applications where precision is critical.
Network performance is another essential factor. Vertical scaling benefits from faster internal communication, resulting in lower latency. In contrast, horizontal scaling can introduce delays due to the need for communication across multiple nodes.
Cost considerations differ significantly between vertical and horizontal scaling. Vertical scaling often requires a substantial initial investment in high-end hardware, along with licensing fees that tend to increase disproportionately with additional cores. For instance, upgrading an AWS instance from a t3.large (around $55.20/month) to a c5.4xlarge (about $490/month) results in an 8x cost increase for only about 5x performance improvement. Horizontal scaling, however, typically relies on a pay-as-you-go model and uses more affordable, commodity hardware. At scale, this approach can be much more economical. For example, serving 5 million users with horizontal scaling can bring the cost per 1,000 users down to about $2.50, compared to $10.00 per 1,000 users when serving just 500,000 users.
Each approach comes with trade-offs. Vertical scaling simplifies management and reduces latency but creates a single point of failure. Meanwhile, horizontal scaling offers redundancy but adds complexity, requiring tools like Kubernetes, load balancers, and distributed monitoring systems. This complexity can lead to higher staffing needs and longer implementation times - re-architecting for horizontal scaling might take weeks, compared to just hours to resize a vertically scaled instance.
Taking these challenges into account, adopting specific practices can help create scalable and resilient analytics systems. Professionals often seek data engineering certifications to master these architectural patterns.
Best Practices for Scalable Analytics
To ensure your analytics system scales smoothly and efficiently, consider these best practices:
- Monitor resource utilization carefully. Keep an eye on CPU and memory usage. Scaling becomes necessary when CPU usage consistently exceeds 70% or memory utilization reaches 80%, ensuring a buffer for performance. Tools like Prometheus and Grafana are excellent for identifying bottlenecks before they affect users.
- Design for statelessness. Avoid storing session data in server memory. Instead, use external caching tools like Redis or Memcached. This simplifies scaling horizontally as demand grows.
- Track and optimize resource usage. Regularly review resource allocation to avoid over-provisioning. For non-production workloads, schedule instances to run only during work hours. When running batch analytics jobs, consider using cloud spot instances, which can be 70% to 90% cheaper than on-demand capacity.
- Leverage Kubernetes autoscalers effectively. Start with the Vertical Pod Autoscaler (VPA) in recommendation mode to determine the best resource configurations. Then, use the Horizontal Pod Autoscaler (HPA) to adjust replica counts based on actual demand. This approach minimizes the risk of "thrashing", where instances are spun up and terminated too frequently.
- Plan for diagonal scaling. Before adding more nodes to a cluster, optimize individual nodes to their most cost-efficient thresholds. This balanced approach, used by companies like Uber during their global expansion, combines the simplicity of vertical scaling with the flexibility of horizontal scaling.
Conclusion
Key Takeaways
Choosing the right scalability strategy depends on your specific workload and growth requirements. Vertical scaling works well for predictable workloads, legacy systems, or datasets smaller than 1 TB. It keeps things simple by avoiding major architectural changes and reducing latency, making it a solid choice for straightforward scaling needs.
On the other hand, horizontal scaling is ideal for systems needing high availability, handling unpredictable traffic spikes, or managing terabyte-scale datasets. While it adds complexity - like load balancing and distributed data management - it eliminates single points of failure and allows for virtually unlimited growth. In many cases, horizontal scaling becomes more cost-effective when user numbers hit the 100,000 to 250,000 range. This highlights the importance of evaluating when to transition to horizontal scaling for maximum efficiency.
For many organizations, a diagonal or hybrid approach strikes the best balance. By combining vertical and horizontal scaling, you can address the limitations of each method. Starting with vertical scaling simplifies early-stage operations, but it's critical to design systems with future horizontal expansion in mind to avoid accumulating technical debt. As Clarifai aptly puts it, "scalability should be designed in from day one, not bolted on later". Keep an eye on CPU usage exceeding 70% and memory usage over 80% as indicators that it's time to scale.
When deciding on your approach, consider factors like data consistency, network performance, and total costs. These elements will guide you toward a well-informed and effective scalability strategy. Professionals looking to lead these transitions often pursue advanced analytics certifications to master high-scale data engineering.
Horizontal vs Vertical Scaling - System Design Interview Guide
FAQs
When should I switch from vertical to horizontal scaling?
When a single machine starts struggling to handle your workload - whether due to hardware upgrades becoming too costly or simply ineffective - it’s time to consider horizontal scaling. This approach involves adding multiple machines to share the load, rather than relying on a single, more powerful system. Horizontal scaling not only helps manage growing or unpredictable demands but also offers a more budget-friendly and adaptable way to distribute traffic across your infrastructure.
How do I keep data consistent when scaling horizontally?
Maintaining data consistency during horizontal scaling is tricky because the system is spread across multiple nodes. To handle this, you can use data partitioning (sharding) combined with replication. This approach distributes your data across nodes while keeping backups to ensure reliability.
For updates, consensus algorithms like Paxos or Raft play a key role. They help coordinate changes and ensure all nodes stay in sync regarding the data's state.
Equally important is picking the right consistency model for your application. Whether you go with eventual consistency or strong consistency depends entirely on your system's needs and how critical immediate accuracy is for your use case.
What’s a practical hybrid (diagonal) scaling path for analytics?
A hybrid diagonal scaling approach blends vertical scaling (boosting the capacity of individual nodes) with horizontal scaling (adding more nodes) to strike a balance between performance and cost. This method adjusts to shifting workloads by combining the advantages of both strategies - handling intensive queries effectively while supporting higher concurrency. With thoughtful planning, it ensures resources are well-balanced, allowing systems to scale smoothly, lower expenses, and stay flexible for ever-changing analytics demands.