
Snowflake in Hybrid Cloud Data Architecture
Managing scattered data across environments is a major challenge for organizations today. Snowflake offers a solution by separating storage from compute and enabling multi-cloud support, addressing the inefficiencies of traditional data warehouses and data lakes. Its pay-per-use pricing, cross-cloud capabilities, and tools like Hybrid Tables simplify workflows, reduce costs, and improve performance.
Key takeaways:
- Hybrid cloud issues: Data silos, performance bottlenecks, and governance challenges.
- Snowflake’s approach: Independent scaling of storage and compute, cross-cloud data sharing, and support for structured and semi-structured data.
- Performance boosts: Automated micro-partitioning and optimized bulk loading (up to 10x faster).
- Cost savings: Pay-per-use model and tools like auto-suspend for idle resources.
Snowflake streamlines hybrid cloud operations, but implementation requires expertise in features like Unistore workloads and multi-cluster configurations. Programs like DataExpert.io’s boot camp can help professionals gain these skills.
Key Problems in Hybrid Cloud Data Architecture
Data Silos and Integration Difficulties
When data is scattered across on-premises and cloud platforms, silos emerge, making it harder to gain real-time insights. Traditional data warehouses require data to be ingested and optimized before processing, which can slow things down. On the other hand, data lakes often turn into unstructured repositories, leaving administrators struggling to catalog and understand the data stored within them.
The situation becomes even more complicated when legacy systems need to integrate with modern cloud platforms. Andrew Reichman from Snowflake's Product and Technology team highlights a key security concern:
"A data lake-based architecture can build role-based access controls into the query platform, but it doesn't own the data and can't fully restrict access to it, allowing users to see or modify data in the object storage console even if they can't get to it through the data platform".
This loophole allows users to bypass security controls at the platform level by directly accessing the underlying cloud storage. The result? Governance challenges that are difficult to address. These integration struggles often pave the way for performance issues, adding another layer of complexity to hybrid cloud architectures.
Performance and Scalability Issues
Legacy systems that tightly couple compute and storage often lead to overprovisioning of resources. Mixing analytical and operational tasks on the same infrastructure can drag down performance. For instance, heavy reporting queries can disrupt critical business operations.
Durga Maturu from BlueCloud explains the downside of this fragmented approach:
"Historically, businesses relied on separate OLTP databases for real-time transaction processing and data warehouses for analyzing historical data. This fragmented approach hindered agility and insights, leading to issues such as data duplication, complex integrations, and sluggish analytical response times".
Another factor to consider is network proximity. If client software operates in a different cloud region than the data platform, latency can increase significantly. Additionally, new compute instances often require a brief warm-up period (2–3 minutes) to populate caches, which can further delay query responses. Beyond performance, these fragmented systems make it harder to maintain consistent security and governance practices.
Security and Governance Problems
Maintaining consistent security across hybrid cloud environments is a major challenge. With data coming from various sources and ownership often unclear, enforcing unified security measures becomes tricky. This is further complicated by the need to comply with regulations like GDPR and CCPA, which vary across jurisdictions.
Many cloud platforms also lack mechanisms like primary or foreign key enforcement, which puts referential integrity at risk. Without consistent governance, businesses often rely on manual processes, which lead to approval delays, unclear access procedures, and slower analytics and operations.
What's New: Architecture Patterns In The Data Cloud | Snowday 2023
How Snowflake Handles Hybrid Cloud Data Architecture
Snowflake addresses long-standing challenges in hybrid cloud data architecture with a design focused on scalability and seamless integration.
Separation of Storage, Compute, and Services
One of Snowflake's standout features is its ability to separate storage, compute, and cloud services. Each of these components scales independently, so you can easily add storage or compute resources as needed. The cloud services layer takes care of tasks like security, metadata management, query optimization, and infrastructure coordination across the platform. With its pay-per-use model, you’re only billed for the compute power you use and the storage you actually consume, avoiding unnecessary costs from overprovisioning.
Multi-Cloud and Cross-Cloud Support
Snowflake operates across AWS, Azure, and Google Cloud through Snowgrid - a cross-region and cross-cloud layer that connects data ecosystems. This setup allows businesses to replicate data for disaster recovery or share live data across different cloud environments, all without the hassle of manual data transfers. Andrew Reichman from Snowflake’s Product and Technology team highlights this capability:
"The core architecture of the Snowflake Data Cloud, and the fully automated replication it supports allows users to share live data across clouds and regions, and fully revoke access to previously shared data".
This approach not only simplifies data sharing but also reduces latency in multi-cloud environments.
Support for Structured and Semi-Structured Data
Snowflake supports a wide range of data types, including structured, semi-structured, and even unstructured data, all within a single platform. This eliminates the need for complex ETL processes that are often required in traditional hybrid cloud setups. Snowflake offers Standard, Iceberg, and Hybrid Tables, each tailored to meet different performance and compliance requirements.
Andrew Reichman emphasizes the platform’s unified approach:
"Snowflake's architecture and the capabilities we give customers since the beginning are a hybrid of warehouse and lake capabilities".
For example, you can query JSON files directly using SQL, which simplifies data pipelines and speeds up the process of turning raw data into actionable insights. These architectural decisions not only streamline operations but also enhance Snowflake's ability to integrate seamlessly into various data ecosystems.
sbb-itb-61a6e59
Snowflake's Solutions for Integration and Performance
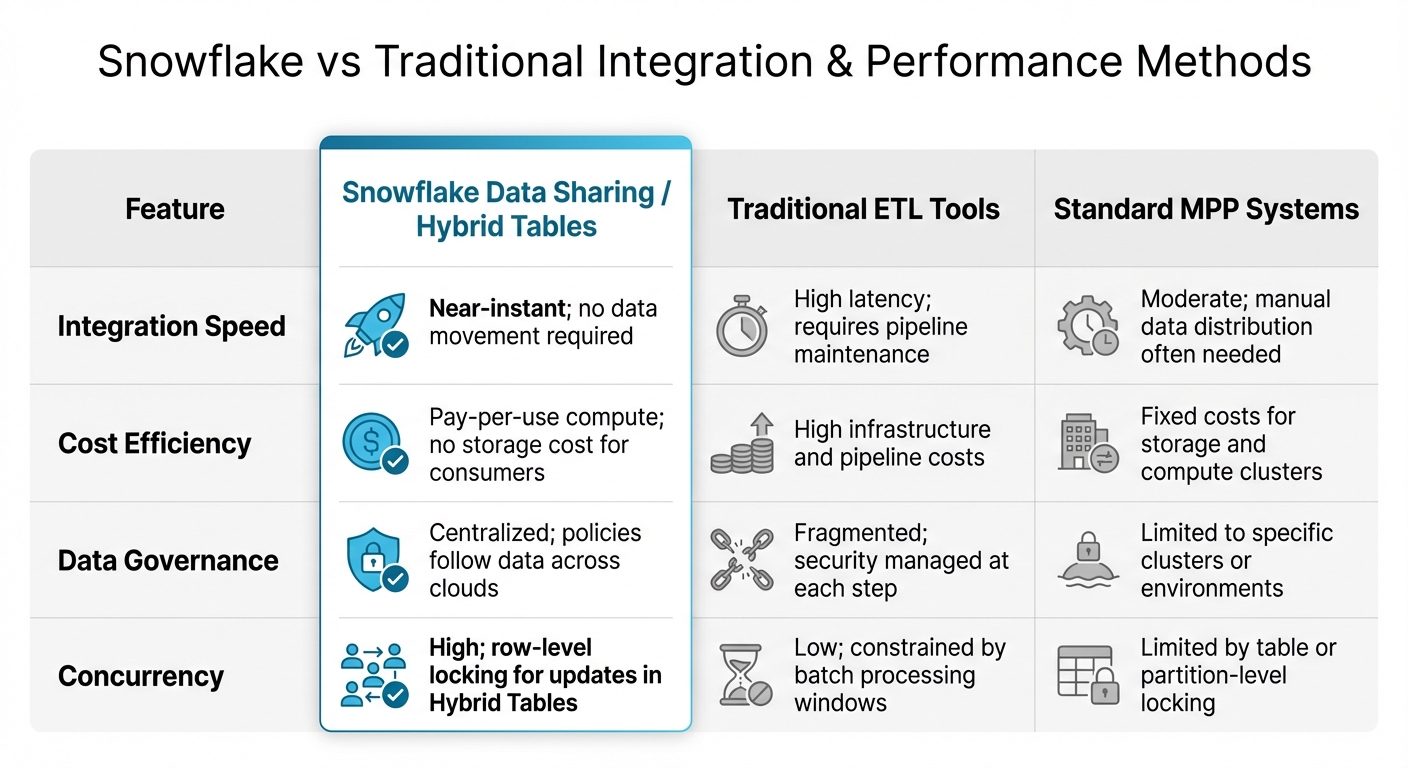
Snowflake vs Traditional Data Integration Methods Comparison
Snowflake takes on the challenges of integration and performance in hybrid cloud environments with tools like zero-copy data sharing, Hybrid Tables, and automated micro-partitioning. These innovations are designed to simplify workflows and boost efficiency.
Data Sharing and Hybrid Tables
With Secure Data Sharing, Snowflake eliminates the need for traditional ETL processes. Instead of physically moving or copying data, it uses metadata to share objects. This means that updates to shared tables, views, or other objects are instantly available to all users, ensuring consistency across accounts and environments. Data providers maintain full control over access and can revoke it at any time, while consumers manage permissions using role-based access control.
Hybrid Tables are another game-changer. They allow transactional and analytical workloads to run side by side. These tables can seamlessly join with standard Snowflake tables in a single query, without requiring complex orchestration or data federation. Initially, data is written to a row store and then asynchronously copied into columnar storage. This dual approach enables bulk load speeds of about 1 million records per minute, with optimized paths running up to 10 times faster than standard methods.
For better query performance, secondary indexes can be defined on frequently used predicates, and foreign keys can help the optimizer create more efficient join plans.
Snowflake doesn't stop there. It further improves performance through automated partitioning techniques.
Performance Optimization with Micro-Partitioning
Snowflake automatically breaks table data into micro-partitions, each containing 50 MB to 500 MB of uncompressed data. Unlike static partitioning, which requires manual upkeep, this automated method reduces data skew and simplifies maintenance. Metadata for each micro-partition - such as value ranges and distinct counts for every column - allows the query engine to skip irrelevant partitions during runtime.
Within these micro-partitions, data is stored in a columnar format. This means only the columns relevant to a query are scanned, not entire rows. For very large tables where query performance might slow down, clustering keys can be defined to group related data. System functions like SYSTEM$CLUSTERING_DEPTH help monitor clustering health and improve pruning efficiency.
Comparison with Standard Integration and Performance Methods
Snowflake's solutions stand out when compared to traditional methods:
| Feature | Snowflake Data Sharing / Hybrid Tables | Traditional ETL Tools | Standard MPP Systems |
|---|---|---|---|
| Integration Speed | Near-instant; no data movement required | High latency; requires pipeline maintenance | Moderate; manual data distribution often needed |
| Cost Efficiency | Pay-per-use compute; no storage cost for consumers | High infrastructure and pipeline costs | Fixed costs for storage and compute clusters |
| Data Governance | Centralized; policies follow data across clouds | Fragmented; security managed at each step | Limited to specific clusters or environments |
| Concurrency | High; row-level locking for updates in Hybrid Tables | Low; constrained by batch processing windows | Limited by table or partition-level locking |
These innovations directly address the integration and performance hurdles commonly faced in hybrid architectures, making Snowflake a strong contender for organizations navigating complex data environments.
Implementation Strategies and Benefits
Snowflake's hybrid cloud architecture combines cost management, strong security measures, and advanced team capabilities to help organizations optimize expenses, maintain compliance, and navigate complex data landscapes.
Cost Efficiency with Pay-Per-Use Scaling
One of Snowflake's standout features is its ability to separate storage and compute, ensuring you’re only charged for what you actually use. Virtual warehouses automatically suspend after 300 seconds of inactivity and resume instantly, so you're not paying for idle resources.
"Snowflake's near-instant scalability enables just-in-time provisioning, so you pay only for the capacity needed." – Andrew Reichman, Snowflake
For smaller operational tasks, starting with an X-Small warehouse is ideal. If demand increases, you can scale by adding clusters instead of enlarging the warehouse itself, keeping costs predictable. Another cost-saving tool is the Egress Cost Optimizer (ECO), which minimizes cross-region transfer fees by routing data through a managed cache. Once the cache is set up, expanding data access to new regions often incurs no additional transfer charges.
By combining these cost-saving features with centralized governance, Snowflake simplifies financial and administrative management across hybrid environments.
Centralized Governance and Security
Beyond cost savings, Snowflake strengthens security and governance through its unified framework. Snowgrid technology enables consistent security and governance policies across AWS, Azure, and GCP, all managed from a single control plane. Role-Based Access Control (RBAC) applies uniformly across standard and hybrid tables, so administrators can manage permissions seamlessly for all workloads. Global data masking policies and row-level security ensure compliance, no matter which cloud region accesses the data.
The Snowflake Trust Center acts as a hub for monitoring security risks throughout the architecture. Best practices include using private connectivity for both inbound and outbound traffic to keep data off public networks. For cross-region data sharing, replication groups allow providers to maintain just one copy of a dataset per region, avoiding the need for multiple copies for each consumer. Additionally, user provisioning can be automated with SCIM (System for Cross-domain Identity Management), ensuring consistent permissions across hybrid setups.
Hands-On Training for Hybrid Cloud Skills
To fully leverage Snowflake’s hybrid cloud features, practical training is key. Gaining expertise involves hands-on experience with Unistore workloads, configuring multi-cluster environments, and applying data constraints. Programs like the DataExpert.io Academy's Winter 2026 Data Engineering Boot Camp (https://dataexpert.io) offer a 5-week immersive course for $3,000.00. The program includes lifetime access to course materials, five guest speaker sessions, and a capstone project.
Participants work on real-world projects, such as implementing row-level locking for high-concurrency updates and executing atomic transactions across hybrid and standard tables to ensure ACID compliance. They also learn to configure multi-cluster autoscaling to adapt to variable workloads, addressing integration and performance challenges efficiently. These skills help minimize latency and improve overall performance, making teams better equipped to handle hybrid cloud environments.
Conclusion
Snowflake's hybrid cloud architecture tackles key challenges that have historically plagued data teams. By integrating transactional and analytical workloads with Hybrid Tables, it eliminates data silos without resorting to complex solutions like data federation or two-phase commit orchestration. The platform's separation of storage and compute ensures elastic scalability, while Snowgrid technology provides consistent governance across AWS, Azure, and Google Cloud - all managed from a single control plane.
These features directly enhance operational performance. For example, row-level locking supports concurrent updates and boosts efficiency. Snowflake's pay-per-use pricing model helps organizations maintain predictable costs, and its enforced primary key, foreign key, and unique constraints uphold data integrity - capabilities often missing in standard cloud data warehouses.
"Snowflake has been immensely impactful for us data scientists. We can consolidate data into one massive data lake as the single source of truth, yet it's all easily queryable." – Matthew Jones, Data Science Manager, Kount
Although Snowflake simplifies hybrid cloud operations, successful implementation requires specialized expertise. Professionals need hands-on experience with Unistore workloads, index design, connection pooling, and multi-cluster configuration, as well as a deep understanding of operational intricacies. Programs like the DataExpert.io Academy's Winter 2026 Data Engineering Boot Camp (https://dataexpert.io) offer practical training to help data professionals master these skills. With the right expertise, organizations can fully leverage Snowflake's capabilities and achieve measurable results in hybrid cloud environments.
FAQs
What are the benefits of Snowflake’s separation of storage and compute in hybrid cloud environments?
Snowflake’s design is built around separating storage from compute, which means you can scale each independently. Need more computing power for a heavy workload? You can add it without increasing storage. Similarly, you can expand storage without affecting compute resources.
This setup is especially useful in hybrid cloud environments. It allows you to fine-tune resource allocation, ensuring you get the performance you need while keeping costs under control. By directing resources exactly where they’re needed, you avoid overspending or disrupting your data storage.
What are Hybrid Tables in Snowflake, and how do they improve data processing?
Hybrid Tables in Snowflake are built to handle both transactional and analytical tasks with ease. They combine the strengths of traditional row-based storage with features like high concurrency and low latency, enabling quick operations such as random reads and writes. This makes them especially suited for tasks like managing application states or delivering precomputed aggregates.
These tables come with row locking and enforce key data integrity rules, such as primary keys, foreign keys, and unique constraints - essential for lightweight transactional applications. What’s more, they integrate seamlessly into Snowflake’s platform, allowing users to manage both transactional and analytical data within a single system. This simplifies the overall architecture and boosts performance for workloads that require a mix of transactional and analytical processing.
How does Snowflake provide security and governance in hybrid cloud environments?
Snowflake delivers strong security and governance capabilities tailored for hybrid cloud environments. Its advanced features safeguard data and streamline access management, ensuring that sensitive information remains protected while being accessible to authorized users.
One standout feature is its ability to enable secure data sharing across major cloud providers like AWS, Google Cloud, and Microsoft Azure. By leveraging secure replication and sharing mechanisms, Snowflake ensures data integrity and confidentiality are never compromised.
To bolster security, Snowflake includes tools such as multi-factor authentication (MFA), single sign-on (SSO), and network policies. These measures ensure that only verified users and services can access critical data. On the governance side, Snowflake offers column-level and row-level security, data classification, and object tagging. These tools help organizations enforce compliance rules and keep track of how data is used.
What’s more, these features work seamlessly across different cloud platforms, simplifying security and governance management in even the most complex hybrid cloud setups.