
Green Data Pipelines vs. Traditional Pipelines
Green data pipelines are reshaping how we process and store data by focusing on energy efficiency without sacrificing performance. Unlike traditional pipelines, which prioritize speed and reliability but often ignore energy use, green pipelines aim to cut power consumption, reduce costs, and lower environmental impact. They achieve this through smarter algorithms, lazy execution, sparse activation, and carbon-aware scheduling.
Key Takeaways:
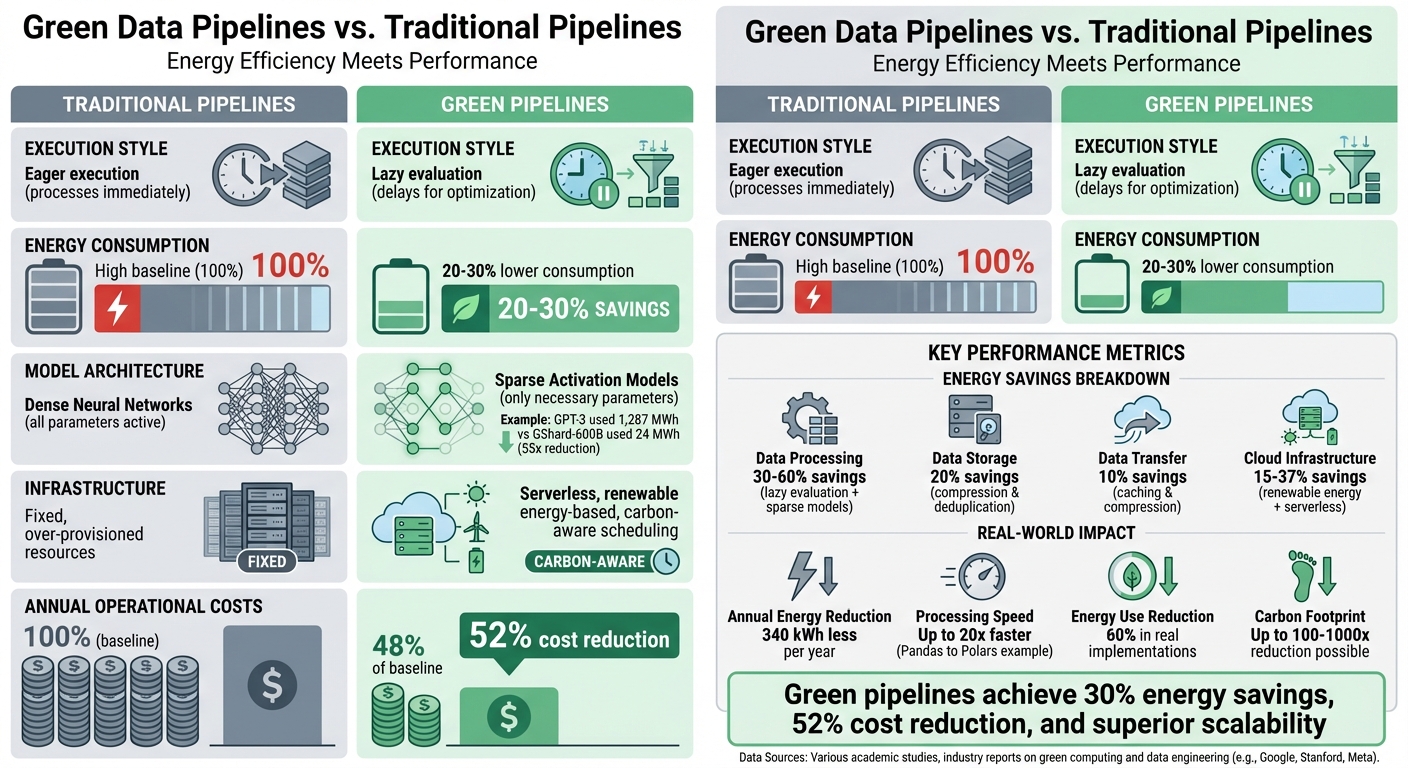
- Energy Efficiency: Green pipelines consume up to 30% less power by optimizing processes like data compression, caching, and lazy evaluation.
- Cost Savings: Lower energy use translates to a 52% reduction in operational costs annually.
- Scalability: Green pipelines handle growing data volumes more effectively with incremental processing and serverless architectures.
- Real-World Impact: For example, switching from Pandas to Polars in lazy mode reduced processing time by 20x and energy use by 60%.
Quick Comparison:
| Feature | Traditional Pipelines | Green Pipelines |
|---|---|---|
| Execution Style | Eager (processes immediately) | Lazy (delays for optimization) |
| Energy Use | High | 20–30% lower |
| Models | Dense Neural Networks | Sparse Activation Models |
| Infrastructure | Fixed, over-provisioned | Serverless, renewable energy-based |
| Cost Efficiency | Standard | 52% lower operational costs |
Green pipelines are not only better for the planet but also a smart financial move. By adopting these systems, businesses can reduce their energy footprint, cut costs, and scale operations effectively.
Green vs Traditional Data Pipelines: Energy, Cost, and Performance Comparison
Goodbye to Spark: Build Efficient Data Pipelines with Polars, DuckDB and More - VFPUG
Energy Efficiency: How Green Pipelines Reduce Power Consumption
Green pipelines are setting new standards for energy efficiency by rethinking how processing is executed. Traditional pipelines often rely on eager execution, which processes operations immediately, even if they aren't necessary. This approach, combined with dense neural networks that activate all parameters for every task, leads to excessive energy use and memory consumption. Green pipelines, on the other hand, take a smarter approach. They use lazy evaluation to delay execution until the system can fully optimize the process and rely on sparsely activated models that engage only the parameters needed. These strategies are further enhanced by scheduling tasks during times when renewable energy is most available.
To put this into perspective, energy-efficient algorithm designs can reduce power consumption by as much as 30% compared to traditional methods. A real-life example comes from Google’s training of an Evolved Transformer model in December 2020. Using TPU v2 hardware in an Iowa data center powered by 78% carbon-free energy, they reduced operations by 1.6x. This setup led to a staggering 57x reduction in CO₂ emissions compared to training a standard Transformer model on P100 GPUs in a typical U.S. data center.
Methods for Reducing Energy Use in Green Pipelines
Green pipelines utilize two standout techniques: lazy evaluation and sparse activation. Lazy evaluation defers operations until the system can optimize the entire query plan, avoiding unnecessary work. For example, in August 2025, researchers in Paris working on the GreenNav traffic prediction pipeline switched from Pandas to Polars in lazy mode. This change allowed them to process datasets up to 8 GB in size, reducing processing time by 20x and energy consumption by 60%, all while maintaining high predictive accuracy (R² ≈ 0.91).
Sparse activation takes optimization a step further by activating only the necessary parameters in a neural network. Dense networks, like GPT-3, consume massive amounts of energy - 1,287 MWh during training, for instance. In contrast, sparsely activated models like GShard-600B used just 24 MWh for training, achieving a 55x energy reduction.
"The choice of DNN, datacenter, and processor can reduce the carbon footprint up to ~100-1000x".
Another critical strategy is carbon-aware scheduling, which shifts workloads to times and places where renewable energy is abundant. For instance, tasks may "follow the sun" or "follow the wind", migrating to regions where solar or wind power is at its peak. Additional energy-saving methods include compressing data with tools like Parquet and Snappy, using serverless computing to ensure resources are active only when needed, and minimizing data transfers through caching and deduplication. These approaches highlight how thoughtful design can lower environmental impact while maintaining performance.
Energy Use Comparison: Green vs. Traditional Pipelines
Green pipelines consistently outperform traditional systems in energy efficiency, cutting cumulative energy consumption by 20% to 30% through techniques like compression, caching, and reliance on renewable energy. The table below outlines key differences:
| Pipeline Component | Traditional Method | Green Method | Energy Savings |
|---|---|---|---|
| Data Processing | Eager execution with dense models | Lazy evaluation with sparse models | 30% – 60% |
| Data Storage | Uncompressed storage | Compression and deduplication | 20% |
| Data Transfer | Unoptimized movement | Caching and compression | 10% |
| Cloud Infrastructure | Standard grid with fixed compute | Renewable energy with serverless resources | 15% – 37% |
Over a year, one study found that a green pipeline consumed 340 kWh less energy than a traditional setup. These savings underscore a broader shift in how data systems are designed, focusing on efficiency and sustainability without compromising functionality.
Cost Comparison: How Green Pipelines Save Money
Lower Operating Costs Through Energy Efficiency
Energy efficiency plays a direct role in reducing Total Cost of Ownership (TCO). With power consumption closely tied to costs, every kilowatt-hour saved translates into financial savings. Green pipelines tackle this challenge with a combination of strategies that work together to cut expenses significantly.
One of the biggest savings comes from reduced energy use. Energy-efficient algorithms can lower power consumption by as much as 30% compared to traditional methods. Pair these algorithms with optimized hardware - such as low-power CPUs and machine-learning accelerators that perform 2 to 5 times better than standard systems - and the savings multiply. Additionally, cloud data centers designed for efficiency operate 1.4 to 2 times better than conventional enterprise setups.
Software optimization also plays a major role in cost reduction. Switching to advanced data processing techniques has demonstrated energy savings of up to 60% in past implementations. These software changes often require minimal upfront investment while delivering ongoing, substantial cost benefits.
Geographic location is another factor that influences costs. Opting for cloud regions with high percentages of carbon-free energy not only reduces emissions but can also lower expenses due to the availability of local renewable energy sources. For example, Google’s Iowa data center achieved an impressive Power Usage Effectiveness (PUE) of 1.11, compared to the U.S. average of 1.59 - a roughly 30% reduction in energy overhead. Over a year, Nishanth Reddy Mandala documented a green pipeline framework that consumed 340 kWh less energy than a traditional setup, with savings distributed across algorithms (30%), hardware (20%), and cloud practices (15%).
When these savings are applied across the board, the financial impact becomes even more compelling.
Annual Cost Breakdown: Traditional vs. Green Pipelines
The combined effect of these optimizations is evident when looking at annual operating costs. Green pipelines, designed for efficiency at every level, have shown a 52% drop in operational costs. These savings come from improvements across energy consumption, hardware, cloud infrastructure, and data practices.
| Cost Category | Traditional Pipeline | Green Pipeline | Savings |
|---|---|---|---|
| Energy Consumption | 100% (baseline) | 60–70% of baseline | 30–40% |
| Cloud Infrastructure | Over-provisioned resources | Dynamic scaling & serverless | 15–20% |
| Hardware/Maintenance | Standard equipment with high idle power | Energy-efficient CPUs & accelerators | ~20% |
| Data Transfer/Storage | Unoptimized movement | Compressed & deduplicated | ~10% |
| Total Operational Cost | 100% | 48% of baseline | 52% reduction |
These savings grow over time, with green pipelines achieving a 20% to 30% reduction in cumulative energy consumption by the end of the first year. While there may be some upfront costs for setup or refactoring, the return on investment (ROI) becomes clear within 12 months. As David Patterson of Google and UC Berkeley aptly put it:
"Perhaps we should add 'energy is money' to Ben Franklin's 'time is money' advice?"
This quote underscores the long-term financial gains of energy efficiency - every watt saved is a step toward lower costs and higher profits.
sbb-itb-61a6e59
Scalability: How Each Approach Handles Growing Data Volumes
When data grows from gigabytes to terabytes, the differences between green and traditional pipelines become strikingly clear. Traditional pipelines often hit a wall when datasets outpace available RAM. In contrast, green pipelines use incremental processing and lazy evaluation to optimize execution plans before even touching the data. This approach not only reduces the computational burden but also cuts energy use significantly. Frameworks designed with energy-efficient algorithms and hardware can slash energy consumption by as much as 40%. Let’s break down how these pipelines manage scaling effectively.
Scaling Methods in Green Pipelines
Green pipelines are built with efficiency in mind, employing techniques that make scaling both feasible and environmentally conscious. One key method is incremental processing. By focusing on only the new data - using timestamps or date partitions - these pipelines avoid the costly task of reprocessing entire datasets. This is especially crucial when working with terabytes of data. For example, in May 2023, Toby Mao, formerly of Netflix, shared how their data team handled terabytes of new data daily using incremental loads. According to Mao:
"Incrementally loading data is one of the most cost effective ways to scale your warehouse."
Another powerful tool is lazy evaluation, combined with parallelism. Libraries like Polars delay execution until absolutely necessary, optimizing the entire query plan beforehand. When paired with Apache Arrow's native parallelization, this approach processes large datasets with far less CPU and memory usage compared to traditional tools like Pandas. A study in August 2025 highlighted this efficiency. Researchers working on the GreenNav CO2 emission prediction pipeline in Paris replaced Pandas with Polars in lazy mode for datasets ranging from 100 MB to 8 GB. The result? Processing times dropped by over 20x, energy consumption fell by 60%, and predictive accuracy (R2) remained solid at 0.91.
Green pipelines also tap into serverless computing, which allows for instant horizontal scaling. This means organizations only pay for - and consume energy for - the resources actively used. Other techniques like liquid clustering and data skipping further enhance scalability by dynamically organizing data and skipping irrelevant portions during queries. Some advanced green pipelines even adopt migratory workloads, shifting computations to distributed micro-datacenters that can take advantage of excess renewable energy.
Scaling Limitations in Traditional Pipelines
Traditional pipelines, on the other hand, face significant challenges as data volumes grow. Many rely on eager execution and in-memory processing, like Pandas, which becomes problematic when datasets exceed available RAM or when operations aren’t optimized for vectorization. This approach often leads to redundant computations and wasted energy.
Another drawback is their reliance on vertical scaling - adding larger, more powerful machines rather than distributing the workload horizontally. While this might temporarily boost capacity, it’s costly and inefficient. Vertical scaling also comes with static energy demands from components like multi-socket CPUs, backup power systems, and cooling, even if only a single GPU is actively used.
The numbers paint a stark picture. By 2026, global data center electricity consumption is expected to surpass 1,000 terawatt-hours (TWh), putting immense pressure on power grids. In contrast, green pipelines can cut cumulative energy use by 20% to 30% over a year compared to traditional systems. The choice isn’t just about performance - it’s about building a pipeline that can scale responsibly as data demands grow.
How to Build Green Data Pipelines
Creating green data pipelines is about making thoughtful, incremental changes to how data is ingested, processed, and stored. It’s not an overnight transformation but a series of strategic decisions aimed at reducing energy usage without sacrificing performance. Companies implementing these strategies are already experiencing noticeable gains in both efficiency and cost savings.
Tools and Platforms for Green Pipelines
The foundation of a green pipeline lies in choosing tools and platforms designed to minimize energy use. For example, Databricks Lakeflow Spark Declarative Pipelines (SDP) optimizes orchestration and parallelism by processing only new or modified data, avoiding the need to scan entire datasets. On the storage side, Delta Lake features like Row Tracking and Change Data Feed enable incremental updates, cutting down on unnecessary data scans. As Databricks explains:
"Incremental refreshes save compute costs by detecting changes in the data sources used to define the materialized view and incrementally computing the result".
For file ingestion, Auto Loader processes only new files, avoiding expensive full-directory scans. Similarly, Snowpipe and Snowpipe Streaming use continuous micro-batching instead of bulk loading, lowering latency and compute costs. AWS contributes to energy efficiency with specialized AI chips like Trainium and Inferentia, which deliver higher performance per watt. Tools like SageMaker Training Compiler and SageMaker Neo further enhance efficiency, speeding up training by up to 50% and 25×, respectively.
When it comes to processing, energy-efficient tools can significantly cut costs. For instance, using Polars in lazy mode optimizes query execution, reducing both processing time and energy consumption. As researcher Youssef Mekouar puts it:
"The careful selection of data processing libraries can reconcile high computing performance and environmental sustainability in large-scale machine learning applications".
Step-by-Step Guide to Building Green Pipelines
To transition into a green pipeline, focus on three main layers:
-
Ingestion Layer
- Use tools like Auto Loader or Snowpipe for incremental data ingestion.
- Enable Row Tracking and Change Data Feed on Delta tables with settings like
delta.enableRowTrackingfor efficient updates. - For non-real-time streaming, opt for "AvailableNow" triggers to process data in batches, reducing continuous compute usage.
-
Processing Layer
- Replace eager-execution libraries like Pandas with lazy-evaluation options like Polars to save energy and time.
- Adopt serverless architectures such as AWS Glue or Serverless SQL Warehouses to avoid idle power consumption.
- Set aggressive auto-termination policies for interactive resources and use Job Compute for non-interactive tasks.
-
Storage Layer
- Automate lifecycle policies in Amazon S3 to archive or delete old data.
- Use columnar formats like Parquet with Snappy compression and apply techniques like compaction and Z-ordering in Delta Lake to optimize storage.
- Query data directly using external tables to avoid duplicating it into a warehouse.
- Right-size your instances with energy-efficient options like Graviton-based processors or AI chips to maximize performance per watt.
By applying these strategies, organizations can cut energy consumption by 20% to 30% annually compared to traditional pipelines. These methods provide a strong starting point for sustainable data practices while opening the door to even greater efficiency gains.
For those looking to dive deeper, DataExpert.io Academy offers hands-on training in data engineering, analytics, and AI, complete with practical projects and access to platforms like Databricks, Snowflake, and AWS. Check it out at DataExpert.io.
Conclusion
Green data pipelines provide a smarter way to manage energy use, cut costs, and scale operations effectively. By leveraging optimized algorithms and sustainable practices, organizations can reduce power consumption by 30% to 60% compared to traditional methods. These improvements don’t just save energy - they lower operational costs, with annual energy savings hitting 20%–30%. Plus, green approaches excel at scaling, managing larger data volumes through tools like lazy evaluation frameworks (e.g., Polars) and sparsely activated neural networks, which demand far less computational power than dense models.
But this shift isn’t just about environmental responsibility - it’s also a smart financial move. For example, Youssef Mekouar’s GreenNav project in August 2025 highlighted how switching from Pandas to Polars in lazy mode slashed processing times by over 20x and energy consumption by 60%, all while maintaining predictive accuracy. Similarly, Google’s work with the Evolved Transformer demonstrated how decisions around model architecture, datacenter location, and processor type can cut carbon footprints by 100x to 1,000x. These kinds of results showcase the enormous potential of sustainable data systems.
Implementing green data pipelines requires technical know-how, from choosing the right libraries to adopting carbon-aware scheduling and serverless architectures. For those looking to gain these skills, DataExpert.io Academy offers hands-on boot camps and capstone projects. Their programs focus on building energy-efficient data architectures using tools like Databricks, Snowflake, and AWS. You can learn more at DataExpert.io.
Adopting green pipelines isn’t just an upgrade - it’s a strategic necessity. Organizations that make this transition today will be better equipped to manage tomorrow’s data demands with greater efficiency, reduced costs, and a more sustainable approach to growth. It’s a win for both business and the planet.
FAQs
What makes green data pipelines more cost-efficient than traditional ones?
Green data pipelines stand out as a more budget-friendly option, largely because they focus on cutting energy consumption, which directly reduces operational costs. By fine-tuning energy use during data processing, these pipelines can slash energy expenses by around 20% to 30% within the first year. This is made possible through smarter cloud computing practices and hardware improvements.
On top of that, green pipelines help trim costs tied to cooling systems, physical infrastructure, and environmental impact by keeping their carbon footprint low. Over time, these savings make it easier for organizations to scale their operations and maintain affordability in the long run.
How do green data pipelines reduce energy consumption compared to traditional pipelines?
Green data pipelines focus on cutting energy use and promoting sustainability in data workflows. They achieve this by using energy-efficient algorithms and architectures that require less computational power. For example, tools like Pandas or PySpark can streamline data processing, helping to minimize resource consumption.
Another smart tactic is reusing shared processes within workflows, which eliminates unnecessary repetition. On top of that, cloud-based solutions or serverless architectures offer dynamic resource allocation, meaning energy is consumed only as needed. Together, these methods help reduce the environmental footprint of data engineering without sacrificing performance or scalability.
What makes green data pipelines scalable and efficient for handling growing data volumes?
Green data pipelines are built to manage increasing data volumes efficiently by leveraging distributed processing frameworks like Spark and Dask. These frameworks split tasks across multiple nodes, ensuring the system can scale seamlessly as data demands grow. This approach helps maintain strong performance without running into bottlenecks.
What sets green pipelines apart is their focus on energy-conscious designs. They streamline workflows by optimizing shared stages and cutting down on redundant processes. By blending scalable architectures with energy-saving practices, these pipelines handle massive datasets effectively while keeping both environmental impact and operational expenses in check.