
Managing Domain Events in Event-Driven Architectures
Domain events are the backbone of event-driven systems. They record business actions that have already occurred, enabling services to communicate without direct dependencies. For example, publishing an event like OrderPlaced allows other services to respond independently, such as sending emails or updating inventory. This approach improves scalability, reduces failures, and simplifies adding new features.
Key takeaways:
- Domain events represent immutable business facts (e.g.,
PaymentProcessed). - Commands vs. Events vs. Queries: Commands initiate actions, events record facts, and queries retrieve data.
- Decoupling services: Events let systems evolve independently without breaking connections.
- Outbox Pattern ensures reliable event delivery, avoiding dual-write issues.
- Versioning and schema management: Add fields, avoid breaking changes, and ensure backward compatibility.
- Governance: Define ownership, maintain clear event naming, and separate internal domain events from external integration events.
Quick Example:
In 2024, BRAC IT replaced a complex REST workflow with a single LoanApplicationSubmitted event. This reduced loan approval times from 4.2 seconds to 820 milliseconds and eliminated daily failures.
Domain events are also key for analytics and AI, feeding real-time insights directly from business processes. To succeed, focus on clear design, reliable publishing, and proper monitoring. Aspiring engineers can master these patterns in a data engineering boot camp designed for real-world systems.
Designing and Structuring Domain Events
How to Name and Structure Domain Events
When naming domain events, always use past-tense business language. For example, terms like OrderPlaced or PaymentAuthorized clearly reflect something that has already occurred. On the other hand, names like CreateOrder are commands, not events, and confusing the two is a frequent pitfall in event-driven architectures.
The payload of an event should provide enough context for independent processing. A well-structured event includes all the necessary data to allow downstream systems to act without needing additional queries. Thin events - those that only carry an ID - force consumers to fetch more details, which can lead to tight coupling and reduced performance.
"Events need to encode intent instead of snapshots. Teams run into trouble when events mirror database rows instead of telling the downstream consumer what changed and why it matters." - Emily Chen, Principal Engineer, Stripe
To ensure traceability and better debugging, every event should include key metadata such as a unique event ID, event time, processing time, causation and correlation IDs, and a schema version. These elements are critical for managing events at scale and distinguishing internal domain events from externally shared integration events.
Domain Events vs. Integration Events
Domain events and integration events serve different purposes and audiences. Domain events are internal to a bounded context and closely tied to the domain model. They are often volatile, changing as the internal model evolves. Integration events, on the other hand, are designed as stable external contracts for other systems or bounded contexts. These events must remain consistent over time, as they function like public API contracts.
One fundamental rule: never expose raw domain events directly to external systems. Instead, use a handler to transform internal domain events into integration events with their own schema. This separation ensures that internal models can evolve without breaking downstream consumers.
| Aspect | Domain Events | Integration Events |
|---|---|---|
| Audience | Internal (your bounded context) | External (other bounded contexts) |
| Stability | Volatile; changes with refactoring | Stable; treated as a public API contract |
| Versioning | Optional/internal | Required and strictly managed |
| Transport | Local database/internal bus | Message broker (e.g., Kafka, RabbitMQ) |
By maintaining this distinction, you can manage changes more effectively and avoid cascading issues across systems.
How to Version Domain Events
Domain events, as immutable records of historical facts, must coexist with the ever-changing nature of domain models. This creates a challenge for versioning. Here are some key principles to follow:
- Add new fields with default values: This ensures backward compatibility.
- Deprecate old fields instead of removing them: This avoids breaking existing consumers.
- Never change the meaning of an existing field: If semantics need to change, introduce a new field or create a new event type.
Techniques like upcasting can help manage older event schemas by transforming them into the latest version at read-time. This allows handler code to work consistently with the current schema. Similarly, using a tolerant reader pattern - where unknown fields are ignored and missing fields have sensible defaults - adds flexibility and reduces the need for tight coordination between teams.
For example, PostNL adopted a strict "no breaking changes" policy. They only add new fields and never remove or rename existing ones. To enforce this, they built a custom message broker with schema registration and validation. This disciplined approach helps prevent silent data corruption, a common issue in distributed systems.
"A schema is not merely a shape of bytes. It is an agreement about meaning." - NILUS Consulting
sbb-itb-61a6e59
Domain vs. Integration events in DDD, why they matter and how they differ
Implementing Domain Events in Distributed Systems
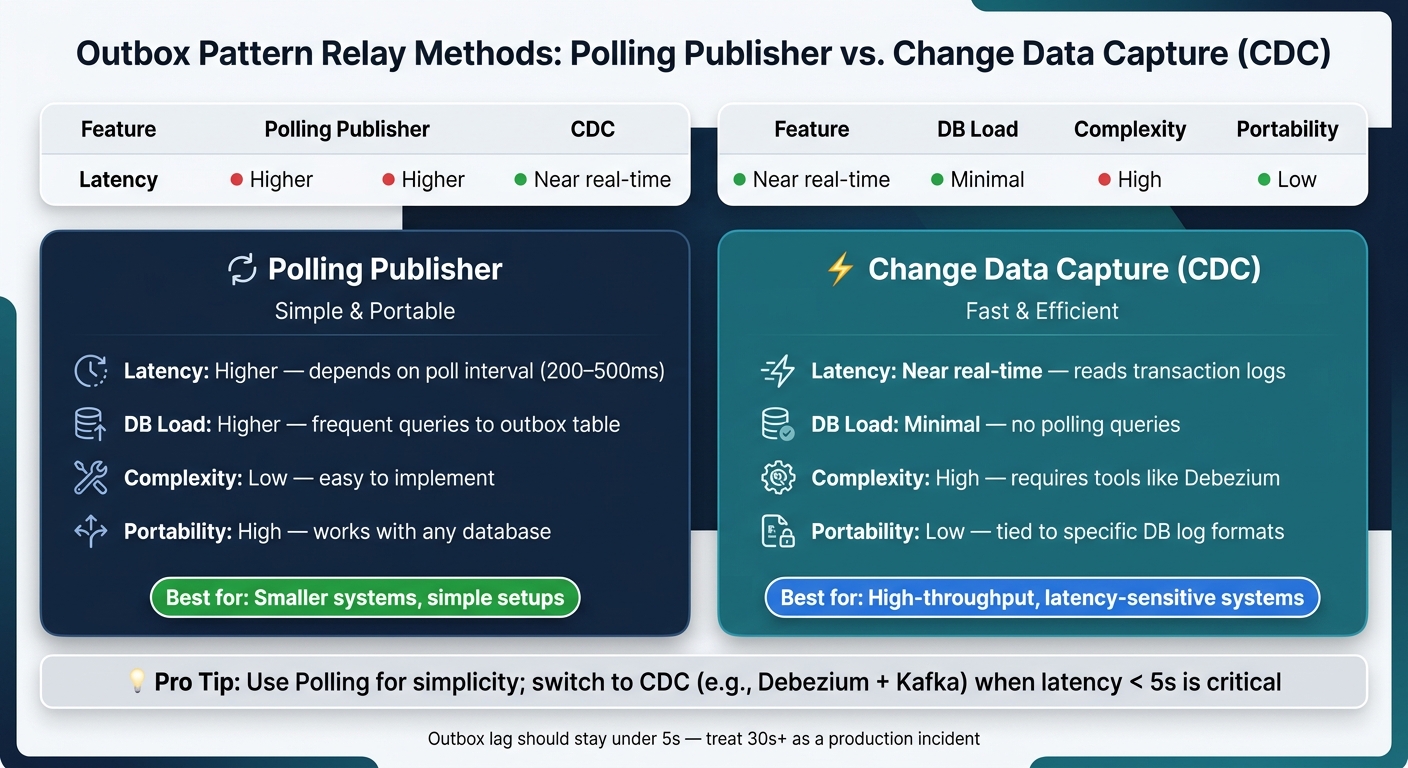
Polling Publisher vs. Change Data Capture (CDC) for Outbox Pattern
Publishing Domain Events from Aggregates
Domain events are created within the aggregate root as part of executing business logic. However, they aren't sent directly to a message broker at that moment. Instead, they are collected and "harvested" by the repository or an interceptor when the aggregate is saved. This approach keeps the aggregate focused on business rules, leaving infrastructure concerns to the persistence layer.
A practical way to automate this process is by using database interceptors. For example, an EF Core SaveChangesInterceptor can automatically gather domain events from aggregates during SaveChangesAsync. This setup ensures business logic remains clean while the infrastructure takes care of delivering the events.
Using the Outbox Pattern for Reliable Event Delivery
When updating a database and publishing to a broker, the lack of a shared transaction boundary can lead to the dual-write problem. If the database update succeeds but the broker publish fails, your system can end up in an inconsistent state.
"Two operations must be treated as a single logical unit, but the infrastructure cannot enforce that unit atomically." - Sudhir Mangla, .NET Architect
The Transactional Outbox Pattern addresses this issue by recording the event in an outbox table as part of the same database transaction that updates the business state. A relay process then publishes these stored events to the broker. This ensures at-least-once delivery, meaning events are never lost, though they might be sent more than once if the relay fails mid-process. To handle this, consumers must be idempotent, typically using an "Inbox" table to track already-processed message IDs.
There are two main methods for relaying events:
- Polling Publisher: A background worker queries the outbox table at regular intervals (e.g., every 200–500ms).
- Change Data Capture (CDC): Tools like Debezium monitor the database transaction log for near real-time event delivery with minimal database load.
Here’s a quick comparison:
| Feature | Polling Publisher | Change Data Capture (CDC) |
|---|---|---|
| Latency | Higher (depends on interval) | Near real-time |
| DB Load | Higher (frequent queries) | Minimal (reads transaction logs) |
| Complexity | Low (simple to implement) | High (requires external tools) |
| Portability | High (works with any DB) | Low (tied to specific DB logs) |
To ensure reliable outbox operations, follow these tips:
- Use
FOR UPDATE SKIP LOCKEDin PostgreSQL orUPDLOCK, READPASTin SQL Server to avoid duplicate processing when running multiple relay workers. - Implement exponential backoff when the broker is unavailable, doubling delays up to a cap (e.g., 5 minutes) to prevent overwhelming the infrastructure during outages.
- Regularly clean up the outbox table to prevent unbounded growth. A cleanup job that deletes processed rows after 7 days is a common practice.
With these measures in place, the system can handle event publishing reliably, setting the stage for effective monitoring and debugging.
Monitoring and Debugging Domain Events
Once reliable event publishing is in place, monitoring and debugging become essential to keep the system running smoothly. Issues like duplicate processing, schema mismatches, or stalled message flows can be difficult to detect without proper observability. A standard event envelope is crucial for tracing: every event should include an eventId, correlationId, causationId, timestamp, and schemaVersion. Without these, debugging failures across multiple services becomes guesswork.
"Without proper metadata design, debugging distributed systems becomes a nightmare of correlating timestamps and guessing at causality." - Nawaz Dhandala, OneUptime
One of the most critical health signals is consumer lag. If lag increases, it often indicates a downstream bottleneck or an under-provisioned consumer. Ideally, outbox lag should remain under 5 seconds, with anything exceeding 30 seconds treated as a production issue.
For messages that repeatedly fail to process (poison-pill messages), route them to a Dead Letter Queue (DLQ) immediately to prevent them from blocking the main pipeline. Any non-zero count in the DLQ should trigger an alert and prompt immediate investigation.
Scaling and Governing Domain Events
How to Avoid Event Spaghetti
As systems grow, unclear ownership of events can lead to tangled dependencies - often referred to as "event spaghetti." This is a common pitfall in large distributed systems and can cause serious challenges.
The best way to avoid this is by enforcing single semantic ownership. Each event stream should belong to only one bounded context, which acts as the authority for that specific business fact. As NILUS Consulting explains:
"Event-driven systems rarely fail because teams cannot publish messages. They fail because nobody can answer a simpler, more dangerous question: who owns the meaning of this event?"
In addition to clear ownership, adopting a consistent Domain.Entity.Action naming convention across teams helps maintain clarity. Another critical practice is separating private domain events - used for internal service communication - from public integration events, which serve as cross-boundary contracts. Mixing these two can lead to tight coupling and brittle systems.
When workflows involve multiple services - four or more - choreography can break down. Relying on services to react independently to events can make workflows hard to trace and debug. In such cases, switching to an orchestrator-based Saga pattern is a better choice. This approach centralizes business rules and makes failure handling more explicit.
By prioritizing clear ownership and consistent naming, you set the foundation for effective governance and lifecycle management.
Governance and Lifecycle Management for Domain Events
Governance ensures that as systems evolve, the meaning of events remains consistent. A data contract registry is key to this process. This registry should document schemas, ownership details, lifecycle states, semantic definitions, and data classifications.
"A proper data contract registry is a mechanism for preserving meaning at scale. It gives event streams the thing they usually lose first under growth pressure: shared semantics." - NILUS Consulting
To manage schema evolution, enforce compatibility checks through your schema registry. This approach prevents breaking changes from disrupting production and gives consumers time to adapt before older versions are retired. When deprecating an event, don’t remove it abruptly. Instead, mark it as deprecated in the registry, notify all consumers, and set a clear timeline for its retirement.
Governance also requires continuous reconciliation. Distributed systems are prone to silent failures - such as missed events or processing errors - that can cause inconsistencies between upstream and downstream models. Automated reconciliation jobs that compare the source state with derived models can catch these issues early, preventing them from escalating.
These practices not only ensure system stability but also make domain events more effective for analytics and AI applications.
Using Domain Events in Analytics and AI Workloads
Once domain events are well-managed, they can power real-time analytics and AI workloads. Because events represent timestamped business facts, they can feed dashboards and models directly without requiring extra API calls or batch data extracts.
To keep this process efficient, design events with enough detail in their payloads so that consumers don’t need to fetch additional data. If an analytics pipeline must call back to the source service to enrich a "thin" event, it reintroduces unnecessary latency and coupling. Including aggregate state - like customer details, item lists, or transaction amounts - within the event payload eliminates this issue.
For AI workloads, it’s essential to embed data classification metadata in the event itself. Fields tagged as sensitive - like PII or PCI - may need masking, encryption, or exclusion from training sets. Including this classification in the data contract registry ensures consistent compliance across all downstream systems interacting with the event stream.
Building Skills in Domain-Driven, Event-Driven Architectures
Key Skills for Managing Domain Events
To manage domain events effectively, you need to develop a mix of technical and analytical skills. Start with event modeling, which involves distinguishing between commands and events. Tools like EventStorming can help you map domain events and define bounded context boundaries clearly. Next, focus on schema management by mastering versioned, immutable schema design. Learn how to use backward, forward, and full compatibility modes to avoid cascading issues when changes occur.
Another critical area is transactional messaging. Patterns like the Outbox and Change Data Capture (CDC) are invaluable for addressing the dual-write problem. Additionally, observability is crucial. Use tracing and monitoring tools to identify and resolve bottlenecks early. Finally, ensure you design idempotent consumers to handle at-least-once delivery scenarios effectively.
By honing these skills, you'll be well-equipped to build scalable, reliable domain events and manage them across event-driven architectures. These capabilities also prepare you to leverage industry-leading tools and platforms designed for event-driven systems.
Tools and Platforms for Event-Driven Systems
The landscape of tools for event-driven architectures is vast, but a few platforms are particularly prominent. Apache Kafka is the go-to choice for high-throughput event streams. For context, LinkedIn operates over 4,000 Kafka brokers, handling more than 7 trillion messages daily. RabbitMQ, on the other hand, excels at complex routing and task-based messaging. For serverless workflows, AWS EventBridge and SNS/SQS are ideal, offering fan-out and retry-heavy flows without requiring infrastructure management.
Here’s a quick comparison of some popular platforms:
| Platform | Ideal For | Ordering | Retention |
|---|---|---|---|
| Apache Kafka | High-throughput streaming, replay | Per-partition | Days to forever |
| RabbitMQ | Complex routing, task queues | Per-queue | Until consumed |
| AWS EventBridge | Serverless fan-out, filtering | Best-effort | None (router) |
| NATS JetStream | Low-latency, edge computing | Per-stream | Configurable |
Beyond brokers, tools like Debezium are widely used to implement the Outbox pattern by streaming database changes directly to Kafka. For orchestrating complex workflows, Temporal and AWS Step Functions stand out as robust options. Schema governance is another critical aspect, often managed with tools like the Confluent Schema Registry, which works alongside formats like Avro or Protobuf to enforce compatibility rules across teams.
"The architecture's quiet superpower is replay. Its quiet killer is the dual-write bug, which the transactional outbox pattern eliminates." - The HLD Handbook
Learning Opportunities with DataExpert.io Academy
If you're serious about mastering these skills and tools, hands-on training can make all the difference. DataExpert.io Academy offers a practical, project-based curriculum designed to help engineers build expertise in real-time data streaming. Their courses cover tools like Apache Kafka, Apache Flink, and Spark Structured Streaming, ensuring you gain both theoretical knowledge and practical experience.
Led by Zach Wilson - an experienced engineer from Airbnb, Facebook, and Netflix - the academy provides over 250 hours of content, 42 hands-on assignments, and access to platforms such as Databricks, Snowflake, and AWS. For a deeper dive, the 15-week Data and AI Engineering Challenge ($7,497) includes mentor support, a capstone project, and training across the full lifecycle of system design and real-time pipelines. For self-paced learners, the Content Pass ($800/year) grants access to the entire library.
"My next goal is to upskill as many data knowledge workers as I can!" - Zach Wilson, Founder, DataExpert.io
Conclusion
Domain events are much more than just a design pattern - they serve as the backbone of a distributed system. They enable services to evolve independently, isolate failures, and introduce new capabilities without altering existing ones. On the flip side, neglecting domain events can result in silent bugs, inconsistent data, and operational challenges that worsen over time.
A practical system redesign has shown that the real drivers of performance improvements are disciplined event design, clear ownership, and reliable publishing methods - not just picking the "right" message broker.
To build stable systems, certain principles are non-negotiable: treat every domain event as a versioned API contract, ensure idempotency for all consumers, use the Transactional Outbox pattern to avoid dual-write errors, and monitor consumer lag as a key health indicator. As Md Sanwar Hossain aptly explains:
"Events are the API contract of the future - but unlike REST contracts, they are asynchronous, durable, and replayable. Design them with the same care you give to your synchronous APIs." - Md Sanwar Hossain, Software Engineer
FAQs
How do I decide what data belongs in an event payload?
When designing event payloads, make sure they carry enough information for consumers to complete their tasks independently. This approach avoids cross-boundary queries, which can lead to tight coupling between services. Focus on including domain-specific facts and key business milestones rather than mirroring database state changes.
Use consumer-driven contracts to validate the necessity of each field in the payload. This ensures that every piece of data serves a clear purpose. If the payload becomes too large or starts including irrelevant data, it's time to split it into smaller, more focused events.
Each event should remain self-contained and stable over time, acting as a reliable historical record that can stand on its own without requiring external context.
When should I use the Outbox Pattern instead of direct publishing?
When you need to maintain atomicity between database updates and event publication, the Outbox Pattern is your go-to solution. Why? Directly publishing events introduces a risk: if a crash or broker failure happens mid-process, your data could end up inconsistent.
The Outbox Pattern solves this by ensuring reliable event delivery while sidestepping the complexity of distributed transactions. Here's how it works:
- Events are written to an outbox table as part of the same database transaction that updates your records. This keeps everything consistent.
- A relay process or a Change Data Capture (CDC) tool then reads from the outbox and publishes the events. This guarantees at-least-once delivery and preserves message order.
By using this approach, you secure both your data integrity and the reliability of your event-driven architecture.
How can I evolve event schemas without breaking consumers?
To update event schemas without disrupting consumers, it's crucial to maintain backward compatibility. This means ensuring older events remain readable by newer versions of the code. Here’s how to do it effectively:
- Add optional fields with default values instead of mandatory ones.
- Avoid removing or renaming existing fields in your schema.
If you absolutely need to make breaking changes:
- Introduce a new event type, such as
OrderPlacedV2, while keeping the original event type functional. - Use upcasting to modify older events at read-time, ensuring they align with the updated schema.
- Implement a schema registry to consistently enforce compatibility rules across your system.
By following these practices, you can evolve your event schemas while minimizing disruptions.