
Metadata-Driven Data Quality: How It Works
Bad data costs organizations an average of $15 million annually, yet most don't measure its impact. Traditional methods for ensuring data quality - like writing SQL scripts for each table - are outdated, time-consuming, and don’t scale. Mastering data engineering allows for more modern, scalable approaches. Enter metadata-driven data quality: a smarter approach that uses metadata (information about data's origin, structure, and lineage) to automate validation, detect issues early, and streamline troubleshooting.
Key Takeaways:
- Centralized Rules: Define data quality standards in a single configuration file (like JSON or YAML) instead of embedding them in every pipeline.
- Shift-Left Validation: Catch errors during transformation phases, minimizing downstream impacts.
- Scalability: One pipeline can manage multiple datasets by referencing shared metadata.
- AI Integration: Machine learning adjusts validation rules dynamically, reducing false alarms.
This approach not only simplifies maintenance but also improves accuracy, helping organizations meet increasing data demands while reducing costs and errors.
Data Quality at Scale: Inside OpenMetadata's Framework with AI & Automation.
sbb-itb-61a6e59
What Is Metadata-Driven Data Quality?
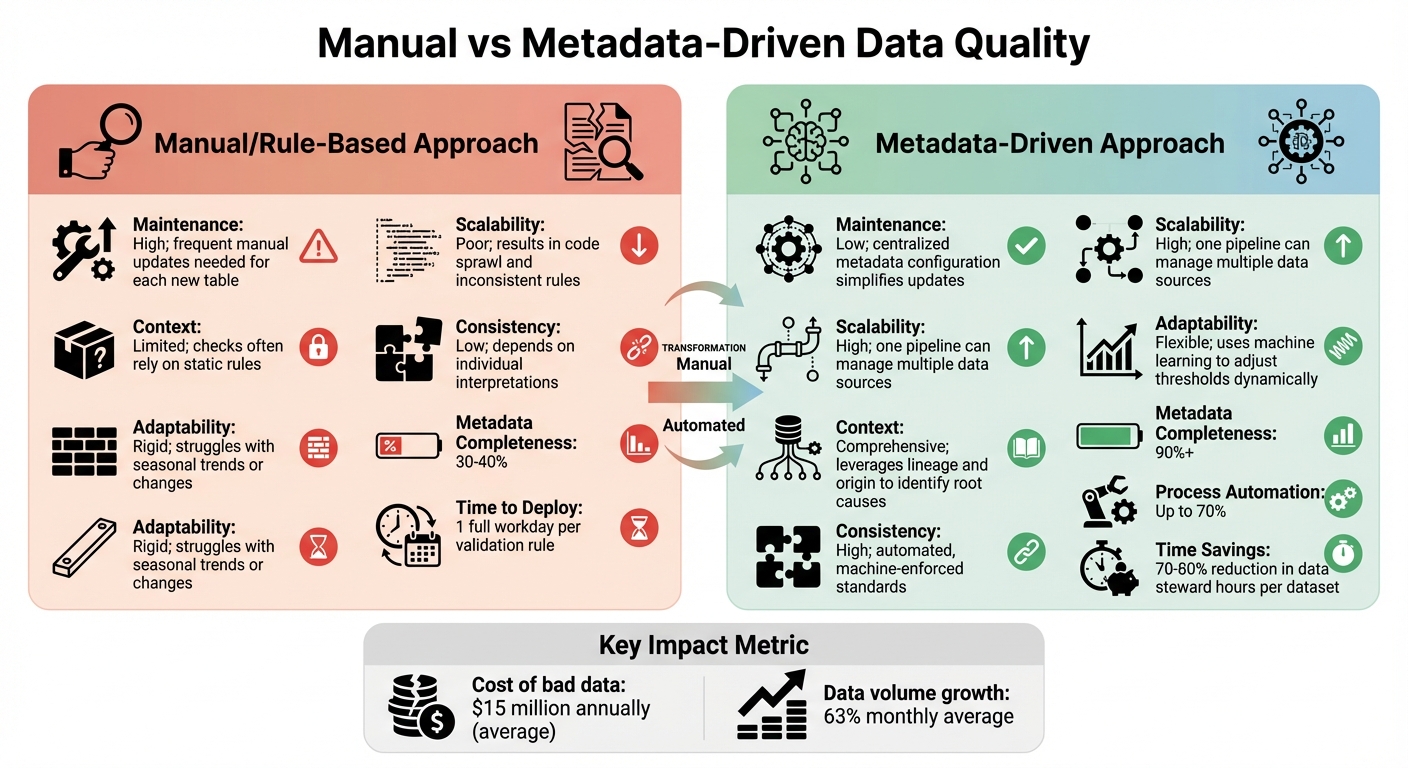
Manual vs Metadata-Driven Data Quality Approaches Comparison
Definition and Core Concepts
Metadata-driven data quality relies on contextual information - like origin, structure, lineage, and ownership - to validate data effectively. This information is stored in formats such as metadata tables, JSON, or YAML and serves as a central reference point. Instead of embedding validation rules directly into each ETL script, this approach uses metadata to validate multiple tables through a single pipeline. When issues arise, metadata helps trace the problem back to its source, transformation history, and affected outputs.
What makes this method stand out is its ability to factor in historical context during validation. Take a sales table as an example: if there's a sudden spike in orders, traditional systems might flag it as an anomaly. However, a metadata-driven system can cross-check the spike against historical patterns, such as a planned anniversary sale, and adjust validation thresholds accordingly. This reduces false alarms and ensures that data quality checks are more accurate.
This approach is a major step forward compared to traditional, manual methods.
How It Differs from Manual Approaches
Manual data quality processes often involve crafting SQL scripts and maintaining spreadsheets for documentation. These methods are labor-intensive and fail to scale efficiently. For instance, deploying a single validation rule for a new data source can take an entire workday. With data volumes increasing by an average of 63% monthly, manual methods quickly become impractical. Furthermore, companies relying on manual processes typically achieve only 30-40% metadata completeness.
Here’s a quick comparison between the two approaches:
| Feature | Manual/Rule-Based Approach | Metadata-Driven Approach |
|---|---|---|
| Maintenance | High; frequent manual updates needed for each new table | Low; centralized metadata configuration simplifies updates |
| Scalability | Poor; results in code sprawl and inconsistent rules | High; one pipeline can manage multiple data sources |
| Context | Limited; checks often rely on static rules | Comprehensive; leverages lineage and origin to identify root causes |
| Consistency | Low; depends on individual interpretations | High; automated, machine-enforced standards |
| Adaptability | Rigid; struggles with seasonal trends or changes | Flexible; uses machine learning to adjust thresholds dynamically |
Automation is a game-changer for organizations aiming to improve data quality and secure your data. By automating up to 70% of processes, companies can reduce the hours spent by data stewards on each dataset by 70-80%, while boosting metadata completeness to over 90%. Yannis Katsanos, Director of Data Science at Ecolab, captures this sentiment perfectly:
"Lakehouse Monitoring has been a game changer. It helps us solve the issue of data quality directly in the platform... it's like the heartbeat of the system. Our data scientists are excited they can finally understand data quality without having to jump through hoops."
The move to metadata-driven systems isn't just about saving time - it's about shifting from reactive fixes to proactive prevention. Instead of discovering issues after they’ve disrupted key reports, these systems catch problems during the transformation phase using "shift-left validation". This approach tackles data quality issues before they escalate, avoiding the "garbage in, garbage out" problem that plagues traditional methods.
These advantages set the stage for building a strong metadata framework, which will be explored in upcoming sections.
Key Components of Metadata-Driven Data Quality
Creating a metadata-driven data quality system involves three key elements that automate validation processes and ensure consistent reliability.
Source Metadata and Data Lineage
Source metadata identifies where data originates - whether it’s from a CRM, ERP, or an external API. Data lineage, on the other hand, traces the entire path data takes, including every transformation or calculation it undergoes. Together, these tools provide transparency into how data flows and enable pinpointing of errors. For example, lineage metadata can identify where a failure occurred and which outputs were affected.
Take Goldman Sachs in 2023: a $1.2 billion accounting error was traced back to a lack of tracking for data origins and transformations. This incident highlights the importance of robust lineage metadata for maintaining financial accuracy. On a different scale, Netflix processes 1.3 trillion viewing records daily, relying on metadata to personalize user experiences and retain customers.
Modern systems also use lineage metadata to introduce circuit breaker logic. This means pipelines can automatically halt or roll back transactions when critical quality checks fail. As Eugenio Doñaque from OpenMetadata explains:
"Data quality is too important to treat as an afterthought. By the time traditional validation catches errors, the damage is done".
This detailed metadata foundation is essential for creating a shared data vocabulary, which is the next piece of the puzzle.
Standardized Data Definitions and Dictionaries
A centralized data dictionary ensures consistency by standardizing terms like "revenue" or "active customer" across departments. These dictionaries house essential details like business rules, KPI mappings, and column descriptions, all in one place. AI-powered tools can even automate the discovery and updating of these definitions.
Data catalogs, a key part of this process, can reduce discovery time by 60% and metadata creation time by 70%, saving data professionals up to five hours per week. Emily Winks, a data governance expert at Atlan, emphasizes the importance of metadata in this context:
"Metadata provides the critical context that makes data quality frameworks effective... Without it, quality rules lack precision, and data issues are harder to trace or resolve".
The growing importance of data catalogs is reflected in the market's growth, projected to rise from $1.38 billion in 2025 to $9.22 billion by 2035. Standardized definitions also work hand-in-hand with clear ownership structures, ensuring accountability throughout the data lifecycle.
Ownership and Accountability Structures
Ownership metadata assigns responsibility for specific data assets to individuals or teams, often data stewards. This ensures that when automated quality alerts are triggered, the system knows exactly who to notify and who is responsible for resolving the issue. Without this clarity, as Jim Kutz points out:
"When no one owns the metadata, it becomes everyone's problem and no one's priority".
For instance, JP Morgan Chase uses advanced data lineage tools to track financial data across its global systems. FedEx employs machine learning to automate metadata tagging for its shipping data, enabling real-time insights that have significantly improved logistics efficiency. Poor data quality costs organizations an average of $12.9 million annually, making clear ownership a financial necessity.
How to Implement Metadata-Driven Data Quality
Creating a metadata-driven data quality system involves a step-by-step process across three distinct phases. Each phase builds upon the last, helping automate validation and reduce the chances of errors reaching production systems.
Phase 1: Establish Data Lineage Frameworks
Start by defining the level of detail you need for data lineage. Dataset-level lineage is useful for tasks like architecture reviews and onboarding new team members. For debugging and tracking sensitive data like personally identifiable information (PII), column-level lineage is essential. Business-level lineage ties technical processes to their business context, making it easier for non-technical stakeholders to understand how the data adds value.
Next, decide how to capture lineage. You can use methods like:
- Pattern-based lineage: Infers data movement by analyzing code patterns.
- Data tagging: Assigns unique identifiers to data as it moves through pipelines.
- Parsing: Scans SQL and ETL scripts to automatically document transformations.
Integrate your chosen method into tools like Dagster or Airflow to capture how and when data flows through your systems. For instance, Magenta Telekom revamped its data infrastructure with Dagster in February 2025, slashing developer onboarding time from months to a single day and eliminating manual workflows. Similarly, HIVED, a logistics company, achieved 99.9% pipeline reliability over three years by replacing cron-based workflows with a unified platform offering end-to-end lineage.
To make lineage actionable, implement tools like a "one-click blast radius" test. This feature allows users to click on any data model and immediately see all downstream dependencies - such as tables, jobs, and dashboards. Also, integrate lineage into CI/CD pipelines to instantly identify downstream impacts of schema changes. As Datadef Guide puts it:
"A perfect graph that is 3 months stale is worse than no graph. Stale lineage creates false confidence".
Without automated lineage, teams spend 40% more time debugging due to manual error tracing. Automating lineage from the start is key to avoiding bottlenecks and errors caused by manual documentation.
Once your lineage framework is in place, the next step is to define metadata standards to further streamline quality checks.
Phase 2: Define Metadata Standards and Policies
Set up a centralized metadata repository to store validation rules. These rules - like null checks, range boundaries, and uniqueness constraints - can be stored in a database such as Azure SQL Server. Your pipelines can then dynamically retrieve and apply these rules without embedding them directly into the code.
Standardize six key data quality dimensions: accuracy, completeness, consistency, timeliness, validity, and uniqueness. Define what "good" looks like for each dimension using metadata. For instance, a "revenue" field might need to be non-null, contain only positive numbers, and follow a specific decimal format. Document these rules along with ownership details and business definitions in the metadata repository.
Assign clear ownership of all data assets. Data stewards should oversee metadata accuracy and coordinate updates. Without clear accountability, metadata standards can deteriorate. Tools like OpenMetadata can centralize metadata, ownership, and lineage into a self-service data catalog.
Embed validation checks into the orchestration layer to interrupt pipelines when critical thresholds fail. Emily Winks explains:
"Metadata-driven data quality uses contextual information about data - such as origin, structure, lineage, and ownership - to identify, diagnose, and resolve quality issues".
Track four main types of metadata:
- Technical: Includes schema details and data types.
- Business: Covers definitions and rules.
- Operational: Tracks processing history and logs.
- Lineage: Maps data movement.
Each type supports automation, from validating schemas to analyzing the impact of changes. Once standards and policies are in place, the focus shifts to automating metadata capture for consistency.
Phase 3: Deploy Automation for Metadata Capture
Building on lineage and standards, automation ensures continuous metadata capture and real-time quality validation.
Leverage tools like Airbyte, dbt, Dagster, and Airflow to automatically capture technical metadata during data ingestion, transformation, and orchestration.
Adopt a "Data Quality as Code" approach using frameworks like Great Expectations or OpenMetadata. For example, OpenMetadata introduced this functionality in its 1.11 release (January 2026), offering a Python SDK that allows engineers to load test definitions from YAML or the UI and run them against in-memory DataFrames before the data reaches the warehouse. This approach helps catch issues earlier during the transformation process.
Develop dynamic pipelines that pull ETL logic from a central metadata source. Frameworks like DLT-META make this possible by enabling pipelines to be driven by JSON or YAML files. As Varun Vemulapalli notes:
"Metadata-driven ETL flips this on its head. Rather than writing N pipelines, you write one generic DLT pipeline that reads from a 'Dataflow Specification' table".
In 2025, Airtel scaled its data governance and discovery efforts across 30+ petabytes of data and over 10,000 active jobs by implementing DataHub as its metadata management backbone.
AI-powered active metadata management can further enhance automation by scanning data sources to identify data types, relationships, and sensitive information using pattern recognition and content analysis. Store validation results in staging tables with flags (e.g., 0 for Valid, 1 for Warning, 2 for Rejected) based on metadata rules. This ensures bad data is flagged rather than silently discarded, giving teams visibility into issues while keeping pipelines operational.
Using AI and Automation to Improve Metadata-Driven Quality
Once you’ve established strong data lineage and metadata standards, the next step is integrating AI to take automation to the next level. Automation ensures metadata is captured consistently, while AI builds on that by identifying patterns, spotting genuine anomalies, and enriching metadata autonomously. The metadata management market, currently valued at $11.69 billion, is expected to grow at an annual rate of 20.9% through 2030. By 2027, organizations using metadata orchestration could see a 70% reduction in the time it takes to deliver new data assets. With this automated groundwork in place, AI can push data quality even further by addressing subtle anomalies and improving metadata.
AI-Powered Anomaly Detection
AI takes anomaly detection beyond static thresholds by learning what "normal" looks like based on historical data. Instead of relying on fixed rules, machine learning models analyze data patterns - like seasonal trends - to identify true anomalies. This dynamic approach adapts as data changes, cutting down on the false positives that often come with rigid rules.
Techniques such as isolation forests and clustering algorithms excel at finding anomalies in complex datasets. They can identify unusual combinations of features that might seem fine individually. For instance, a $50,000 transaction in a rural area at 3:00 AM might raise a flag, even if the amount and location are independently valid. AI also adds semantic understanding, recognizing that terms like "USA" and "United States" refer to the same entity, which allows for more sophisticated checks beyond basic text matching.
Platforms like Anomalo use unsupervised machine learning to automatically create models for individual datasets, identifying statistically significant anomalies without requiring manual setup. These AI tools can improve performance by over 90% while slashing operational overhead by up to 80%. A good starting point is to implement "Shadow Mode", where AI-generated rules are logged but not enforced. This helps validate accuracy and refine detection methods before they are used as hard constraints. Focus on high-priority assets, such as financial reports or customer-facing AI systems, where the impact of quality issues is greatest.
Beyond just spotting anomalies, AI also plays a proactive role in improving metadata, ensuring it stays relevant as data evolves.
Automated Metadata Enrichment
AI simplifies the creation and upkeep of metadata, a task that would otherwise require significant manual effort. Large Language Models (LLMs) can translate natural language descriptions into executable code, like SQL queries or Python scripts, making it easier to create quality constraints. For example, Gemini can analyze data profiles and suggest YAML-compliant data quality rules for Dataplex, speeding up the creation of foundational quality frameworks.
AI-driven profilers can detect schema drift, such as new fields or changes in data types, and automatically update validation rules to keep pipelines running smoothly. It can also suggest titles, descriptions, and classifications for assets by analyzing naming conventions, query histories, and organizational patterns.
To strike a balance between automation and oversight, use a Human-in-the-Loop (HITL) approach. Set confidence thresholds for AI recommendations: high-confidence changes can be automated, while lower-confidence suggestions should be reviewed by data stewards. Additionally, every AI-generated enrichment should be labeled and logged in an audit trail to ensure transparency and compliance with metadata provenance requirements.
Measuring Success and Maturity Levels
When leveraging automated metadata capture and AI-driven tools, it's crucial to track progress and maturity to ensure your efforts are paying off.
Key Performance Indicators
Focusing on the right metrics can reveal whether your metadata initiatives are effective. Poor data quality can lead to significant financial losses, so measuring improvements is essential for protecting your bottom line.
Start with efficiency metrics to quantify time savings. For example, organizations using metadata management often report a 40-60% reduction in time spent searching for and interpreting data, along with 30-50% faster development of new data pipelines.
Next, consider quality metrics to assess your data's health across six key dimensions. Use tiered thresholds to prioritize fixes: "Gold" assets maintain ≥99% accuracy, "Silver" assets achieve 95-98%, and "Bronze" assets fall below 95%. Track issues detected before they affect downstream systems, and measure Mean Time to Resolution (MTTR) to monitor how quickly problems are addressed. Effective metadata management can lead to 50-70% faster resolution of data quality issues.
Finally, evaluate adoption metrics like how often data catalogs are used, the completeness of metadata (e.g., assets with descriptions and owners), and the ratio of automated to manual fixes. Successful organizations automate around 70% of their data quality processes, compared to just 19% in less effective ones.
These metrics not only measure current success but also guide ongoing improvements, ensuring that your metadata practices evolve alongside your data ecosystem.
Stages of Maturity
Organizations typically move through four stages of metadata maturity:
- Descriptive Stage: At this initial stage, the focus is on "what happened." Basic rule-based checks and data contracts are used to validate missing values and formatting. This approach is manual and reactive, addressing issues only after they arise.
- Diagnostic Stage: Here, the focus shifts to "why it happened." Data profiling and historical trend analysis help identify root causes. While still reactive, this stage lays the groundwork for smarter detection by uncovering patterns in metadata.
- Predictive Stage: This stage asks "what might happen." Machine learning and anomaly detection are applied to time-series metadata. By using adaptive thresholds instead of static rules, organizations can catch problems before they impact downstream systems and reduce false alarms.
- Prescriptive Stage: The final stage focuses on "what actions to take." Automated remediation, self-calibrating rules, and intelligent incident grouping become standard. At this level, failures are prevented proactively through validation and closed-loop incident management, ensuring similar issues don't recur.
To advance through these stages, prioritize the most critical assets - start with the 50-100 assets that are essential for business decisions or AI models. Replace static rules with machine learning-based anomaly detection, and use circuit breakers to automatically halt pipelines when critical thresholds are breached. Closing the loop with postmortems and using incident data to create new prevention measures is key to achieving full maturity.
Conclusion
Metadata-driven data quality isn't just a technical tweak - it's a game-changer in how organizations manage and trust their data. Shifting from manual, table-by-table validation to automated, metadata-powered systems allows businesses to scale quality checks across countless tables without the headache of constant maintenance. This approach weaves seamlessly into every phase of the metadata lifecycle.
With 84% of CEOs worried about data quality and poor data costing companies an average of $15 million per year, ignoring quality is no longer an option. Organizations need proactive frameworks that catch issues early, provide context for resolving problems, and continuously improve through closed-loop incident management.
Start small by focusing on critical assets - those 50-100 key data points driving business decisions or fueling AI models. Use column-level lineage to quickly trace and fix issues, and don't overlook circuit breakers to prevent downstream contamination. As your processes mature, machine learning-based anomaly detection becomes a powerful tool for moving toward predictive and prescriptive capabilities.
The journey from basic descriptive methods to advanced prescriptive maturity takes time, but each step adds tangible value. Whether you're just setting up data contracts or implementing automated remediation, the ultimate goal is clear: turn data quality from a reactive challenge into a proactive advantage.
As data ecosystems expand, metadata-driven quality grows with them. By adopting this approach, organizations can turn their data management hurdles into strategic opportunities.
FAQs
What metadata is needed to get started?
To get started with metadata-driven data quality, you'll need to gather essential metadata elements like data sources, data schemas, lineage, and quality rules. These components are crucial for automating and embedding quality checks seamlessly into your data engineering workflows.
How do I prevent false alerts from anomaly checks?
To cut down on false alerts from anomaly checks, consider using dynamic data testing strategies that adjust to evolving data patterns. For example, predictive range tests based on time series models can pinpoint actual anomalies while keeping false alarms to a minimum. On top of that, applying machine learning techniques for thorough data quality checks enhances detection precision, creating a more dependable system with fewer false positives.
How do I roll this out without breaking pipelines?
To introduce data quality checks without causing disruptions to your pipelines, it’s best to take a gradual approach. Start by implementing checks alongside your current workflows - this way, they run in parallel and don’t interfere with operations. Leverage tools like automated alerts or logging systems to keep an eye on results and tackle problems as they arise.
For more complex scenarios, consider using metadata-driven frameworks. These can simplify the process, manage problematic data efficiently, and support scalability. This approach helps maintain the stability of your pipelines while ensuring data quality standards are met.