
Unified Storage with Apache Iceberg: Future Trends
Apache Iceberg is transforming how businesses manage streaming and historical data. By combining these into a single storage system, it eliminates complex pipelines and data silos. Iceberg's features like ACID transactions, schema evolution, and time travel make it a reliable choice for real-time analytics, AI workloads, and large-scale data management. Companies like Netflix and Alibaba already use Iceberg to handle petabytes of data daily, balancing speed and cost efficiency.
Key Highlights:
- Unified Storage: Combines real-time and historical data for seamless querying.
- Core Features: Metadata-driven operations, schema flexibility, and partition management.
- Real-Time Analytics: Integrates with tools like Flink and Kafka for near-instant insights.
- AI Support: Works with formats like Lance for faster data retrieval in machine learning tasks.
- Future Updates: Iceberg v3 and v4 focus on improving metadata handling, deletion efficiency, and collaboration with other table formats like Delta Lake.
Iceberg is becoming the go-to option for organizations looking for a vendor-neutral, scalable solution to manage both streaming and batch data in one platform.
Apache Iceberg Explained in 10 Minutes – Everything You Need to Know!
sbb-itb-61a6e59
Key Features of Apache Iceberg for Unified Storage
Apache Iceberg Partition Transforms: Performance Comparison vs Traditional Systems
Apache Iceberg brings a modern approach to unified storage, offering features that simplify storage management in production environments. Unlike older formats that require extensive rewrites, Iceberg uses metadata-only operations to handle changes efficiently.
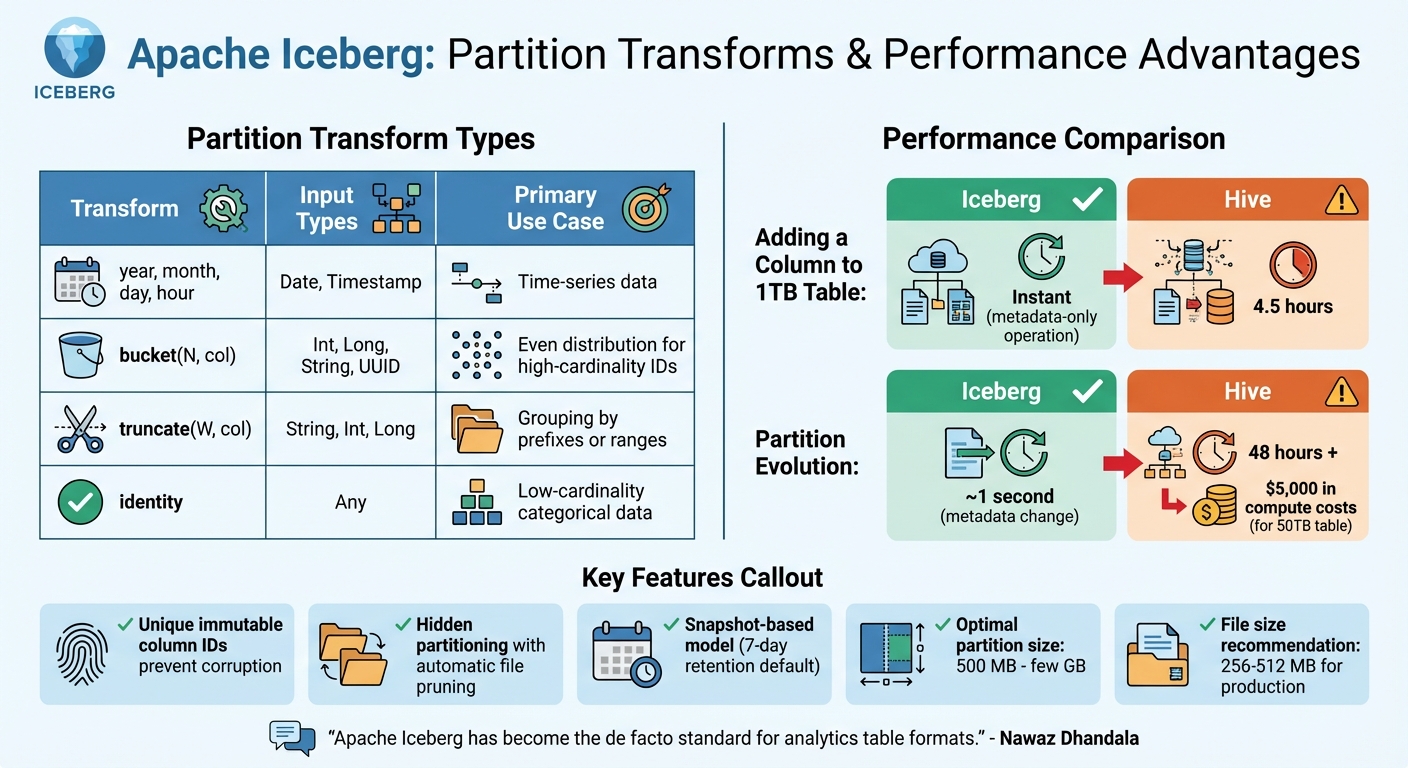
One standout feature is its use of unique, immutable IDs for every column. This eliminates the risk of data corruption during column renaming or reuse. For instance, adding a column to a 1TB table with Iceberg takes no time at all, compared to the 4.5 hours it would take in a traditional Hive table.
"Apache Iceberg has become the de facto standard for analytics table formats." - Nawaz Dhandala, Author
Iceberg also excels in managing schema and partition changes. Its metadata layer allows seamless transitions, such as moving from monthly to daily partitioning, without altering existing data. Thanks to its hidden partitioning feature, users can query based on data values, while Iceberg automatically optimizes file pruning using the active partitioning scheme.
Another key benefit is its snapshot-based model. Every write operation creates a new, immutable version of the table, ensuring that readers always see a consistent view - even during concurrent writes. This enables powerful features like time travel, which is useful for auditing, debugging, or rolling back to previous states. Typically, snapshots are retained for seven days to balance recovery options with storage efficiency.
Schema Evolution and Partitioning
Iceberg handles schema changes with ease, distinguishing itself from traditional data warehouses. Changes like adding, dropping, renaming, or reordering columns are treated as metadata updates, making them nearly instantaneous, regardless of table size. It also supports safe type promotion, so data types can be widened (e.g., from int to long) without data loss or migration.
Recent updates have expanded its capabilities, adding support for nanosecond-precision timestamps, native geospatial types, and the VARIANT type for efficiently managing JSON-like data.
Partitioning in Iceberg is equally advanced. It uses transforms to derive partition values from source columns automatically. These transforms include:
- Temporal transforms: Group data by year, month, day, or hour for time-series data.
- Bucket transform: Use Murmur3 hashing to evenly distribute high-cardinality data.
- Truncate transform: Group data by prefixes or ranges.
- Identity transform: Ideal for low-cardinality data like regions.
| Transform | Input Types | Primary Use Case |
|---|---|---|
year, month, day, hour |
Date, Timestamp | Time-series data |
bucket(N, col) |
Int, Long, String, UUID | Even distribution for high-cardinality IDs |
truncate(W, col) |
String, Int, Long | Grouping by prefixes or ranges |
identity |
Any | Low-cardinality categorical data |
Partition evolution is handled as a quick metadata change, taking about one second. In contrast, traditional Hive systems might take 48 hours and cost $5,000 in compute resources to repartition a 50TB table. For best performance, partitions should be sized between 500 MB and a few GB, while files smaller than 100 MB can reduce read efficiency.
These features make schema and partition management both flexible and efficient.
Data Versioning and Time Travel
Iceberg's robust management of schema and partitions directly supports unified storage by accommodating diverse data types with ease.
Each write operation generates an immutable snapshot, creating a detailed version history of the table. Snapshot isolation ensures consistent views even during concurrent writes. The metadata structure, which links JSON metadata to manifest lists and files, ensures atomic commits.
Time travel queries let users access specific snapshot IDs or timestamps, making it easier to audit changes, debug issues, or recover from errors. This is particularly valuable for workflows like change data capture and incremental processing. Iceberg v3 also introduced row lineage tracking, which identifies changes at the row level to streamline real-time analytics.
"Iceberg is the layer that makes it possible by bringing warehouse-grade reliability to data lake storage." - Alex Merced, Developer Advocate, Dremio
Iceberg's metadata design enables fast scan planning with O(1) remote calls. For production tables, file sizes between 256 MB and 512 MB are ideal. Regular maintenance tasks, such as expiring snapshots and compacting data files, help sustain performance. Iceberg v3's deletion vectors further improve read speeds by marking deleted rows efficiently.
With features like versioning, time travel, and efficient deletion handling, Apache Iceberg serves as a reliable storage layer for both streaming data and historical analysis.
Streaming Data Integration with Apache Iceberg
Bringing streaming data into unified storage systems requires a delicate balance between fast data ingestion and efficient file handling. Apache Iceberg, with its snapshot-based architecture, is well-suited for streaming workloads, but integrating it effectively demands careful planning, often requiring the skills taught in a data engineering boot camp.
Platforms like Flink and Kafka can write directly to Iceberg tables, combining real-time data ingestion with historical analysis. However, maintaining this balance isn't easy. For instance, a Flink job with 1-minute checkpoints generates around 1,440 files daily per partition. Without proper maintenance, this can lead to thousands of small files (1–10 MB each), which can slow down query performance by as much as 100×.
Real-Time Analytics with Iceberg
Streaming engines like Flink and Spark can detect and process new Iceberg snapshots in intervals as short as 5–60 seconds. This allows for near real-time analytics on data stored in Iceberg tables. Flink's FLIP-27 integration further enhances this by enabling smooth transitions between batch and streaming data processing. Users can toggle between historical snapshots and incremental updates seamlessly.
In December 2025, Alibaba implemented a system capable of processing 40 GB/s across 3 PB of data. They used Fluss for sub-second query responses as a "hot" layer, while Iceberg handled historical analysis as a "cold" layer. This approach eliminated the need for dual writes and significantly reduced Flink's state size from 50–100+ TB by leveraging Fluss's primary key enforcement.
"The line between batch and streaming processing is blurring. Apache Iceberg... is at the forefront of this shift, promising to unify these paradigms in a single, scalable framework." – Tomer Ben David
Redpanda's Iceberg Topics simplify the conversion of Kafka streams into governed Iceberg tables, handling Parquet batching and ensuring exactly-once commits in a single step. Additionally, the Flink Dynamic Iceberg Sink, introduced in late 2025, allows for dynamic writing of streaming data into multiple Iceberg tables. This feature supports automatic schema evolution and partition adjustments without restarting jobs.
While Iceberg's real-time analytics capabilities are impressive, managing storage for streaming data still presents operational hurdles.
Challenges in Streaming Data Storage
High-frequency streaming commits can create unique challenges in unified storage systems. For example, frequent commits may generate up to 3,600 manifest lists per hour or 86,400 per day, significantly increasing metadata overhead. Traditional file-system-based lakehouses often struggle with latency at the minute level due to the burden of file commits and metadata operations.
"Metadata becomes the bottleneck, not data throughput [in high-frequency streaming commits]." – Apache Fluss (Incubating)
One common approach to addressing this issue is using Merge-on-Read (MoR) mode for streaming workloads. Instead of rewriting entire files (as in Copy-on-Write mode), MoR writes changes to delta files, reducing write latency. Automatic compaction processes then consolidate small files into larger Parquet files. Some systems, like RisingWave, integrate this compaction directly into the streaming engine.
For organizations that require sub-second latency, tiered storage architectures often work best. The "Streamhouse" model combines a hot streaming layer (using tools like Fluss or Kafka) for immediate decision-making with Iceberg as a cost-efficient layer for historical analytics. Query engines can perform union reads, allowing a single SQL query to access both real-time logs and historical Iceberg files without data gaps or overlaps.
Future Trends in Apache Iceberg and Unified Storage
Apache Iceberg is steadily transforming into a universal data layer designed to support AI workloads, enhance metadata management, and promote cross-format collaboration. These advancements strengthen Iceberg’s ability to unify real-time and historical data, breaking down silos in the process. This evolution addresses the increasing demand for unified storage solutions capable of managing both structured analytics and machine learning workflows seamlessly, a skill set often covered in data engineer bootcamps. With its established support for streaming data, Iceberg is paving the way for the next generation of data storage systems.
AI and Machine Learning Support
Apache Iceberg’s File Format API (introduced in v1.11.0) separates file schema from storage, enabling seamless integration with AI-focused formats like Lance, Nimble, and Vortex - without requiring major changes to processing engines. For instance, Lance delivers performance up to 2,000× faster than Parquet when retrieving 100 million small records, while Nimble provides 2–3× faster decoding, minimizing GPU idle times during training.
Another key feature includes column families, which allow updates to specific data elements, such as vector embeddings, without rewriting entire tables. Iceberg v3 also improves the VARIANT data type, making it more efficient for handling JSON and API payloads - a crucial enhancement for AI data pipelines. Additionally, built-in support for GEOMETRY and GEOGRAPHY data types enables advanced location-based AI tasks, such as route optimization and spatial analysis.
"Finalizing the File Format API marks a major milestone for Apache Iceberg. It enables clean extensibility, encourages innovation across file formats, and prepares Iceberg for the next generation of analytics and AI workloads." – Apache Iceberg Community
Advances in Metadata Management
Iceberg v4 proposals aim to streamline metadata handling with single-file commits, consolidating all metadata changes into one file per commit. This reduces write amplification and improves performance in high-frequency streaming environments. Additionally, the transition from Avro to Parquet for metadata storage enables query engines to perform columnar reads, reducing memory consumption by only projecting necessary statistics.
Iceberg v3 introduces deletion vectors, which optimize row-level deletions by tracking removed rows more efficiently. This method speeds up updates by as much as 10× compared to traditional MERGE operations. The new row lineage feature assigns unique identifiers to rows, enabling efficient Change Data Capture (CDC) and incremental processing without requiring expensive full-table scans. Snowflake’s announcement in March 2026 of public preview support for Iceberg v3 highlights the importance of these features, including row lineage for CDC and deletion vectors for both reads and writes.
"Iceberg v3 moves the entire industry forward to a more performant, capable, and interoperable world." – Databricks Blog
Collaboration with Other Table Formats
Iceberg v3 enhances interoperability by aligning key features - such as deletion vectors, row lineage, and the VARIANT data type - with Delta Lake and Apache Parquet. This alignment allows for cross-format compatibility without requiring data rewrites. The Iceberg REST Catalog API further simplifies integration by providing a standardized interface, enabling engines like Spark, Flink, and Trino, as well as platforms like Snowflake and Databricks, to interact with the same data regardless of the underlying catalog.
Looking ahead, developers aim to create a fully integrated open lakehouse by allowing Delta and Iceberg clients to share metadata and tables directly. The File Format API plays a crucial role in this vision, making file formats both pluggable and engine-agnostic. This flexibility supports integration with AI-focused formats like Lance and Vortex.
"In future Delta Lake and Apache Iceberg releases, we want to build on this foundation so that Delta and Iceberg clients can use the same metadata and thus, can share tables directly." – Databricks Blog
Conclusion
Apache Iceberg has grown into a versatile data layer that bridges the gap between real-time streaming and historical analytics, eliminating the need to duplicate data across operational and analytical systems. Through its metadata-driven design, automated compaction processes, and compatibility with both batch and streaming engines, Iceberg has become the backbone of modern data lakehouses. These lakehouses are now capable of handling AI, machine learning, and real-time analytics workloads in tandem. With features introduced in v3 and the anticipated updates in v4 - such as deletion vectors, row lineage, and single-file commits - Iceberg is paving the way for the convergence of table and stream processing.
By using Iceberg, organizations no longer need to maintain separate systems for streaming ingestion and batch processing. Instead, they can rely on a unified platform that supports both. Real-world use cases have demonstrated its ability to achieve sub-10 millisecond latencies while managing high-throughput ingestion tasks. This unified storage approach not only simplifies data pipelines but also enhances the ability to perform real-time analytics and power AI workloads effectively.
"Iceberg is quickly becoming the default for organizations that want one consistent table format across streaming, lakehouse, and AI workloads - without locking themselves into a single vendor ecosystem".
This vendor-neutral design allows data engineers to build flexible systems that are ready for future challenges.
For those looking to stay ahead, hands-on experience with unified storage and Iceberg’s latest features is crucial. Platforms like DataExpert.io Academy (https://dataexpert.io) offer boot camps and capstone projects to help you master modern stream-fed lakehouse architectures.
FAQs
How does Iceberg unify streaming and historical data?
Apache Iceberg brings together streaming and historical data through an open and scalable table format. It supports key features like ACID transactions, schema evolution, and time travel, making it a powerful tool for managing data. Its metadata layer ensures efficient querying across both real-time and historical datasets. Processing engines such as Spark and Flink take full advantage of Iceberg's capabilities, allowing seamless integration of streaming and batch workloads. This creates a unified storage approach, perfect for building flexible and efficient data lakehouse architectures.
How do time travel and snapshots work in Iceberg?
In Apache Iceberg, time travel enables you to query specific snapshots, which are unchangeable views of a table captured at particular moments. Each snapshot comes with metadata, including the snapshot ID, timestamp, and parent snapshot ID. This metadata allows you to revisit past states of your data, making it useful for tasks like debugging, auditing, or recovering information. Snapshots are automatically generated with every write operation, ensuring a thorough and dependable record of your data's history.
How do I prevent small-file and metadata bottlenecks with streaming writes?
To tackle small-file and metadata challenges in Apache Iceberg, consider using partition-aware compaction. This method consolidates small files while keeping ingestion and latency-sensitive reads unaffected. Another effective approach is to schedule regular compaction processes. These processes merge small files into larger ones, cutting down on metadata overhead. Together, these strategies enhance metadata management, boost query performance, and support smoother streaming operations, especially in workloads that often deal with small-file problems.